Self-Supervised
Self-Supervised Learning 可以看作是 Unsupervised Learning 的一种,因为没有有标注的数据,也就是没有 Label。
与 Supervised 进行对比:

关于 Self-Supervised NLP Model,主要有两类:BERT、GPT
BERT
BERT 本质为 Transformer 的 Encoder
训练任务
- Masking Input:在输入随机 mask,然后训练输出接近 Ground Truth,也就是还原被 mask 的部分
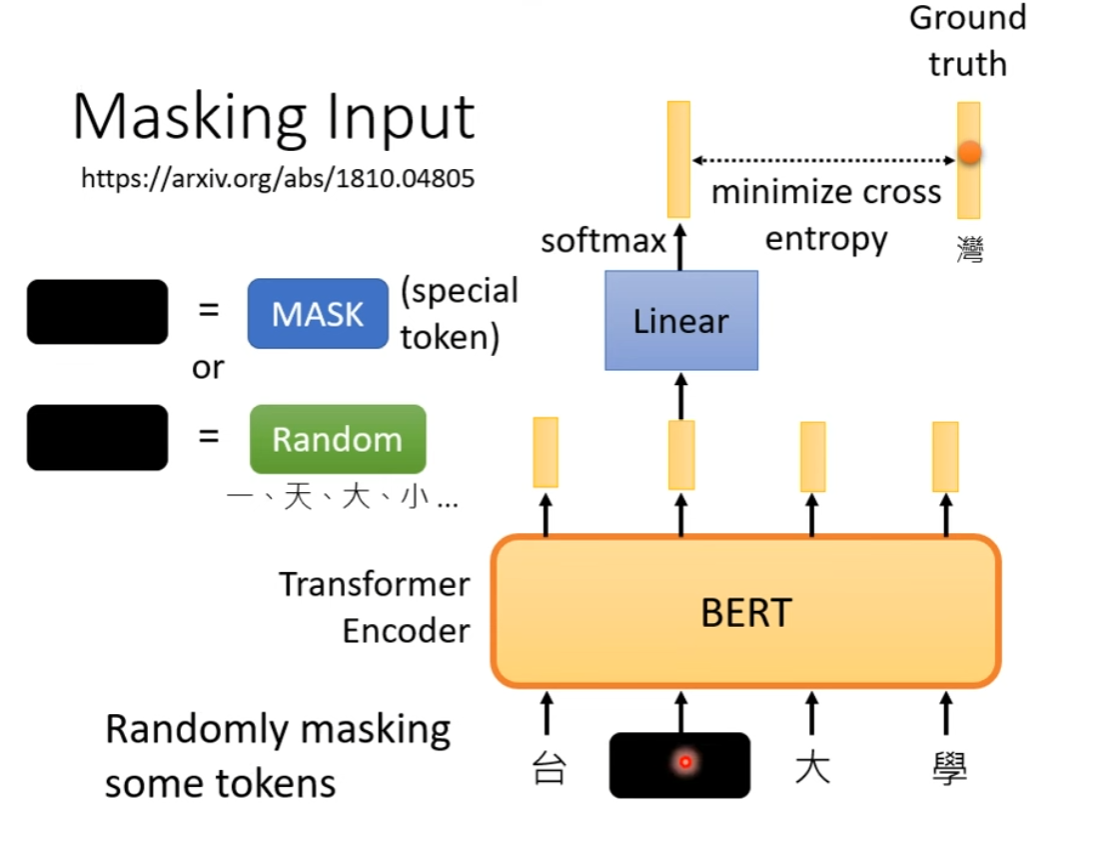
训练时,BERT 连带着 Linear 一起训练。
- Next Sentence Prediction:输入两个句子,看前面的
CLS向量,通过 Linear 进行二分类,判断后面的句子是不是应该接在前一个句子后的。

比较简单的任务,发现对 BERT 训练的帮助不大。
Downstream Task
通过这些任务进行的 Pre-Train,BERT 学会了做填空题,但经过 微调(Fine-tune) 他可以用在其他的地方上。

Testing

How to Use BERT
Pre-Train (Self-Supervised, that is Unsupervised) + Fine-Tune (Supervised) ⇒ Semi-Supervised
以下都是 NLP 的例子,但是换成语音、图片等也同理,因为他们也是一排向量。
Case 1: One Sentence, One Class
E.g. Sentiment analysis

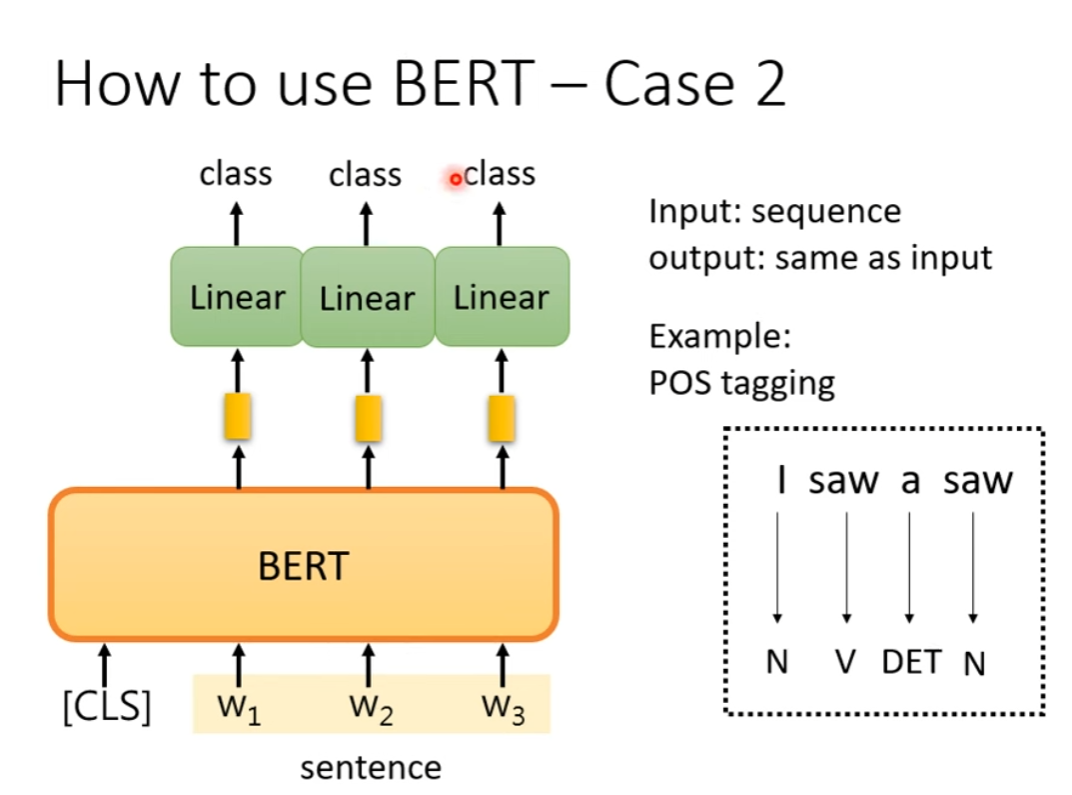
Case 2:One Sequence, One Sequence of the Same Length
E.g. POS tagging
Case 3:Two Sequences, One Class
E.g. Natural Language Inference (NLI)

也可以把文章和评论都投入模型,推测评论是支持还是反对文章的立场。

Case 4:Two Sequence, Two Integer
E.g. Extraction-Based Question Answering
Extraction-Based 要求答案原文一定在文章有出现过。

过程:
- 初始化两个向量,一个代表答案开始的地方,一个代表答案结束的地方,分别与文章的 hidden 层向量相乘,过 softmax,最大位置处即为始末位置。


Pre-Train A Seq2Seq Model


Why Does BERT Work
一种常见的说法

BERT 计算出来的 embeddings,会代表一个 token 的含义,含义越接近的,在向量空间距离越小。


这是因为训练完形填空的时候,BERT 要依靠上下文预测被 mask 的词,所以根据语境学会了词的含义。

但是…
BERT 还可以用在蛋白质、DNA、音乐的分类
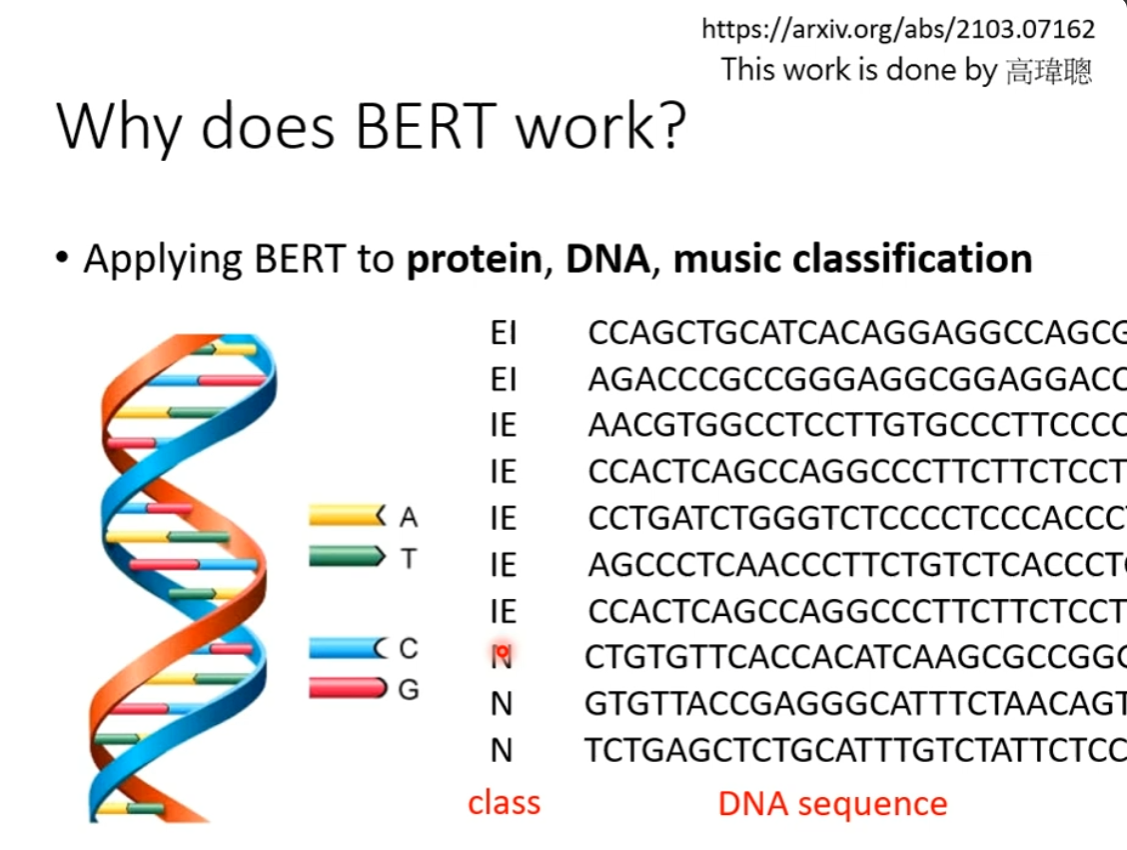
我们把 ATCG 分别对应为一个单词


结果竟然非常好!明明是为 English Pre-Train 的,但是给了一个就英文而讲,胡乱拼凑的句子,表现竟然很好。
Multi-lingual BERT
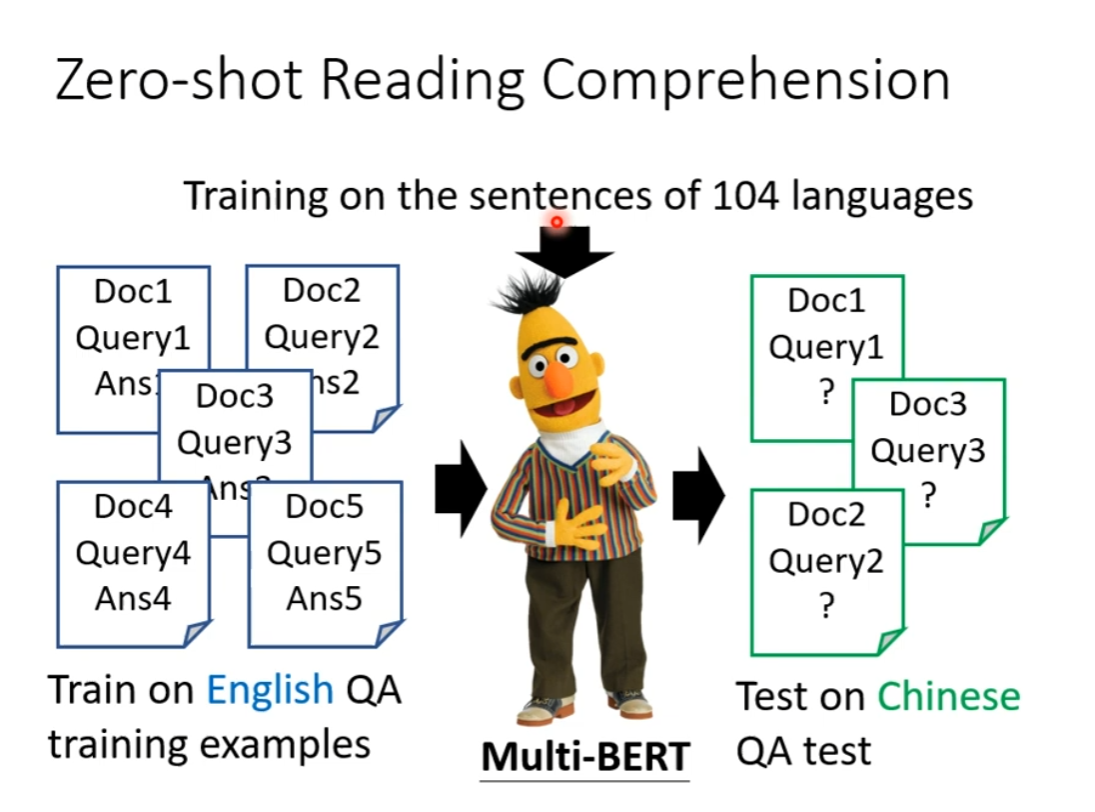
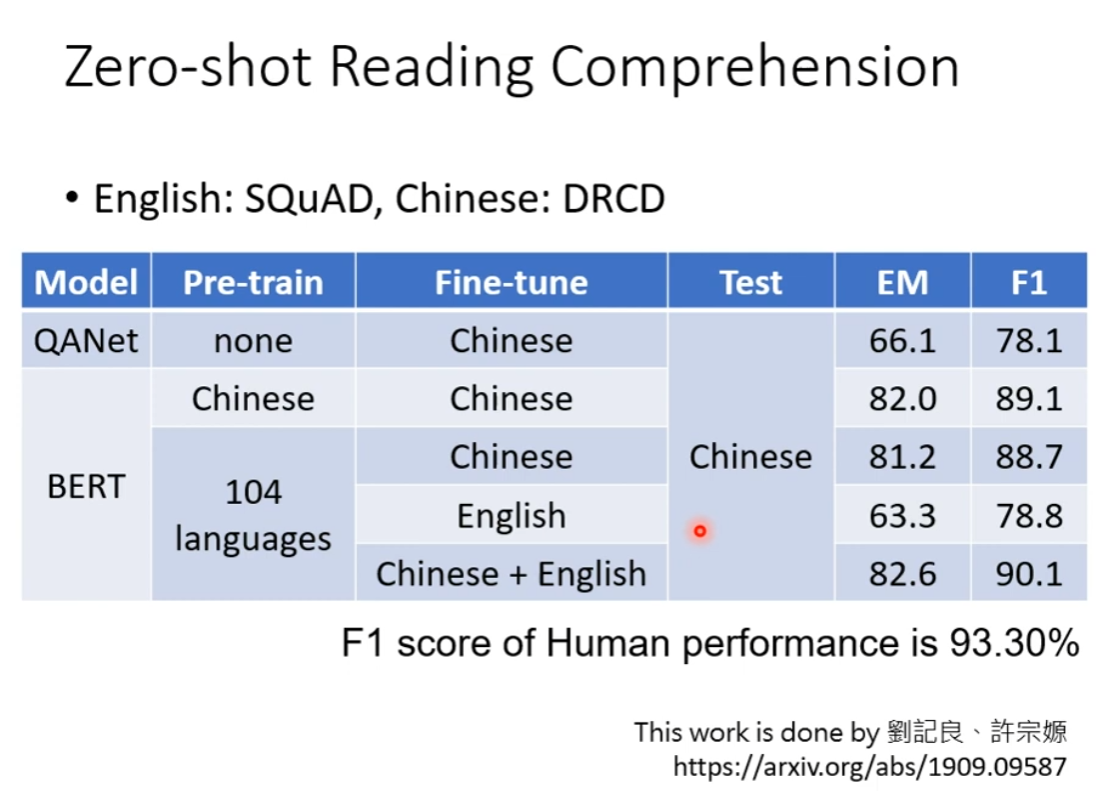
就算不用 Chinese 进行 Fine-tune,而是用 English,然后直接进行 Chinese 的 Test,得分竟然也很高。
一种简单的解释:对于 BERT,不同的语言并没有那么大差别

那 BERT 又是如何做到填空的时候不填错语言的呢?也就是说,他的 embedding 里,一定隐藏了不同语言的信息。



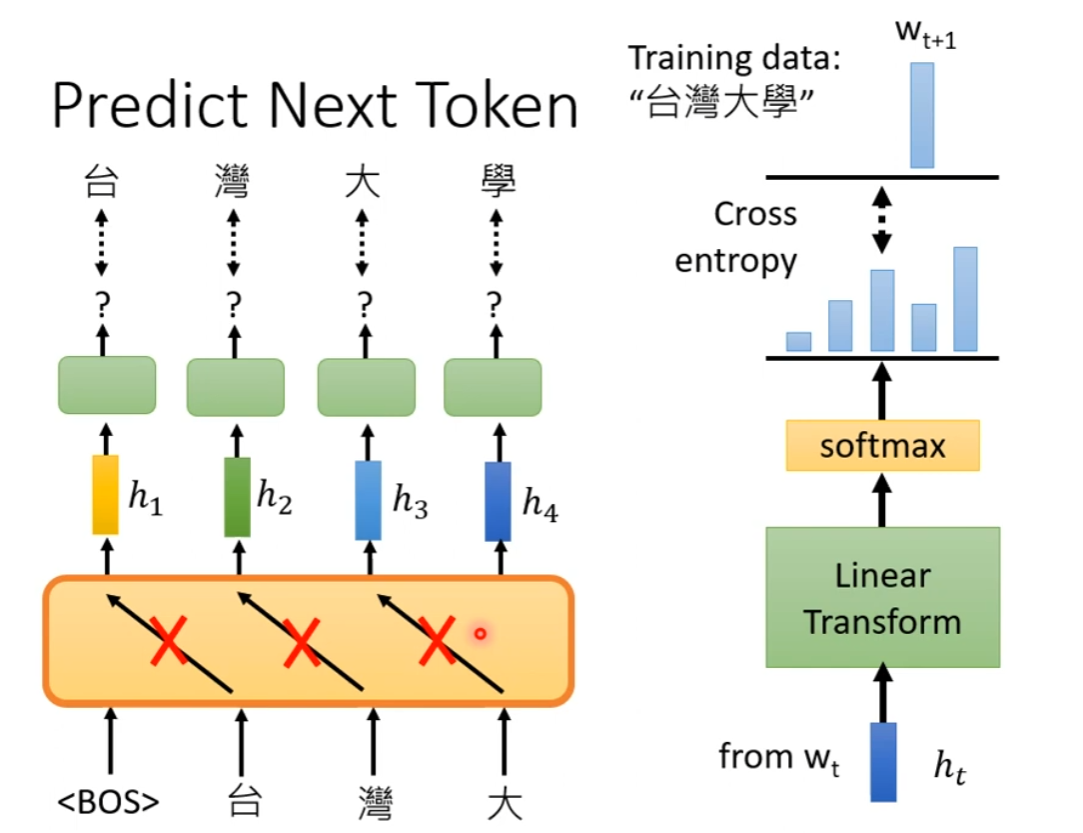
GPT
GPT 的架构,本质为 Transformer 的 Decoder,去掉 Cross-Attention 的部分。
训练任务
- Predict Next Token:预测下一个词

Beyond Text
