Auto-Encoder 也是 Self-Supervised Learning 的一种方法,不需要 labeled data。
Basic Idea
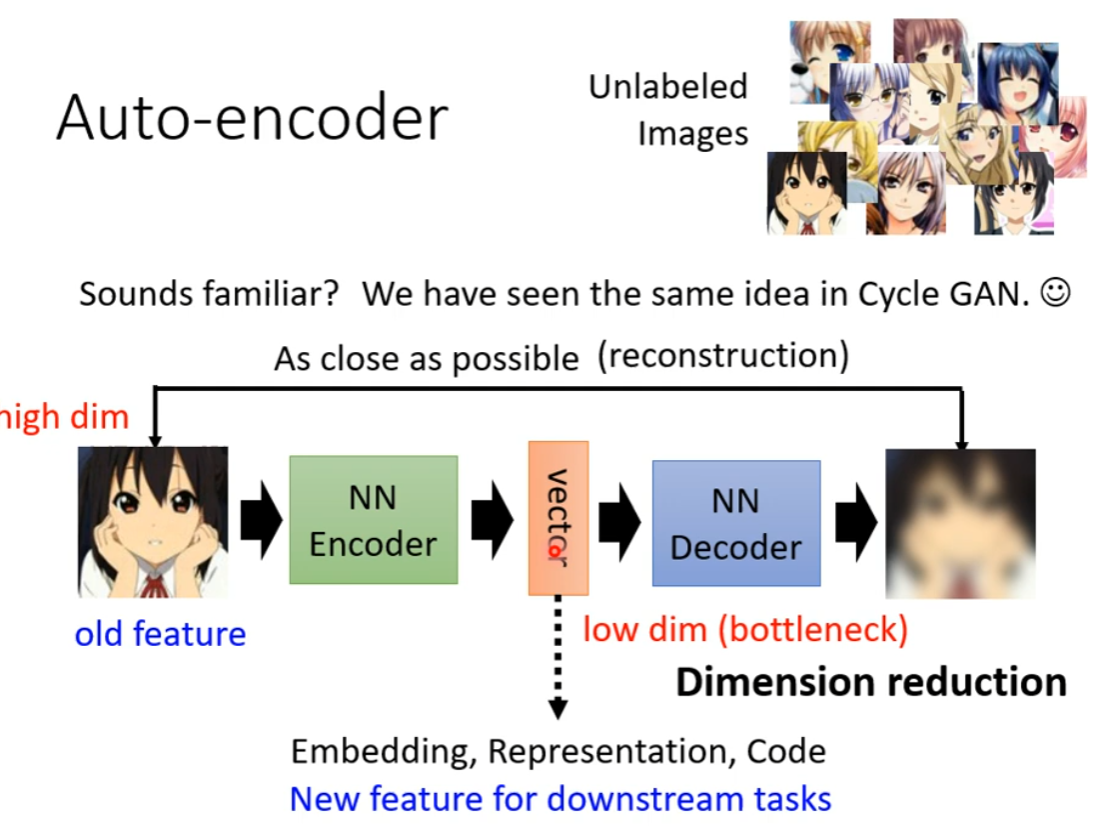
经过 Auto-Encoder,可以把复杂的高维输入向量转为一个维度比较低的向量。
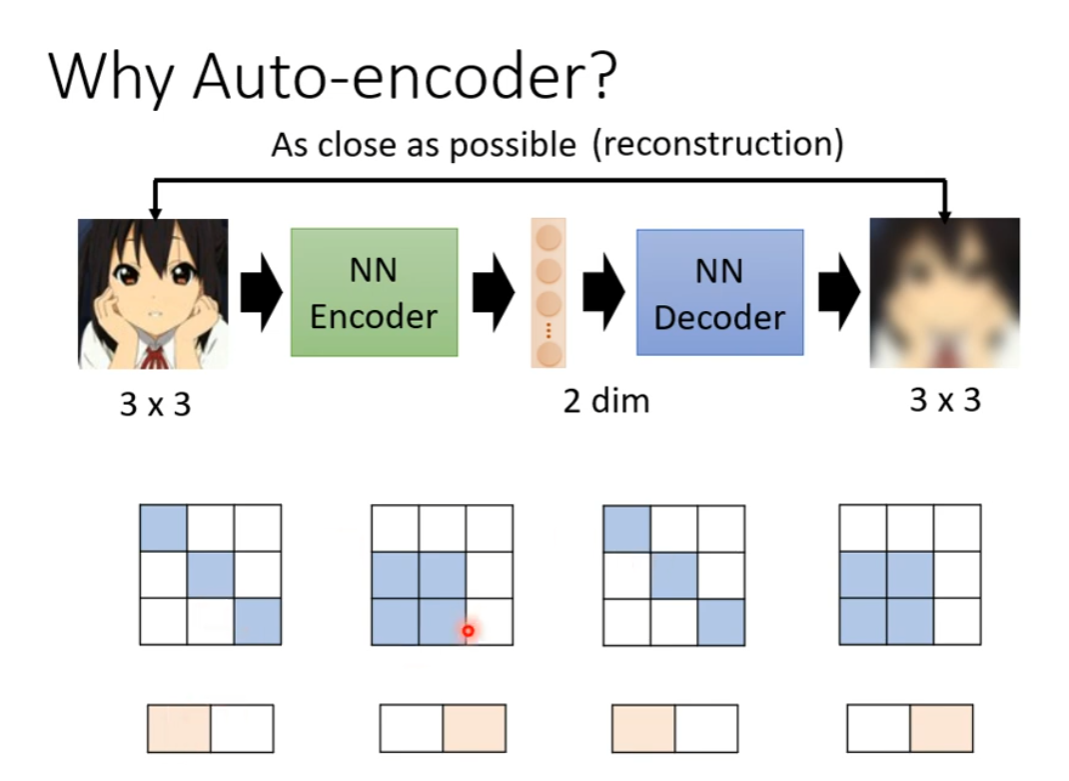
因为他会提取输入的特征,找到复杂多变的输入的不变的特征并表示,就可以做到高效压缩信息了。

这个就类似于 BERT 的训练过程中,我们加入 mask,然后要求模型还原没有 mask 的初始内容。所以 BERT 本质其实是一个 De-noising auto-Encoder。
Feature Disentanglement
AE 虽然能有效提取信息、压缩维度,但是里面包含的多样的信息,是混杂在 embedding 里的,因此 Feature Disentanglement 的议题就是确定哪些维度分别对应哪些信息。


Application: Voice Conversion
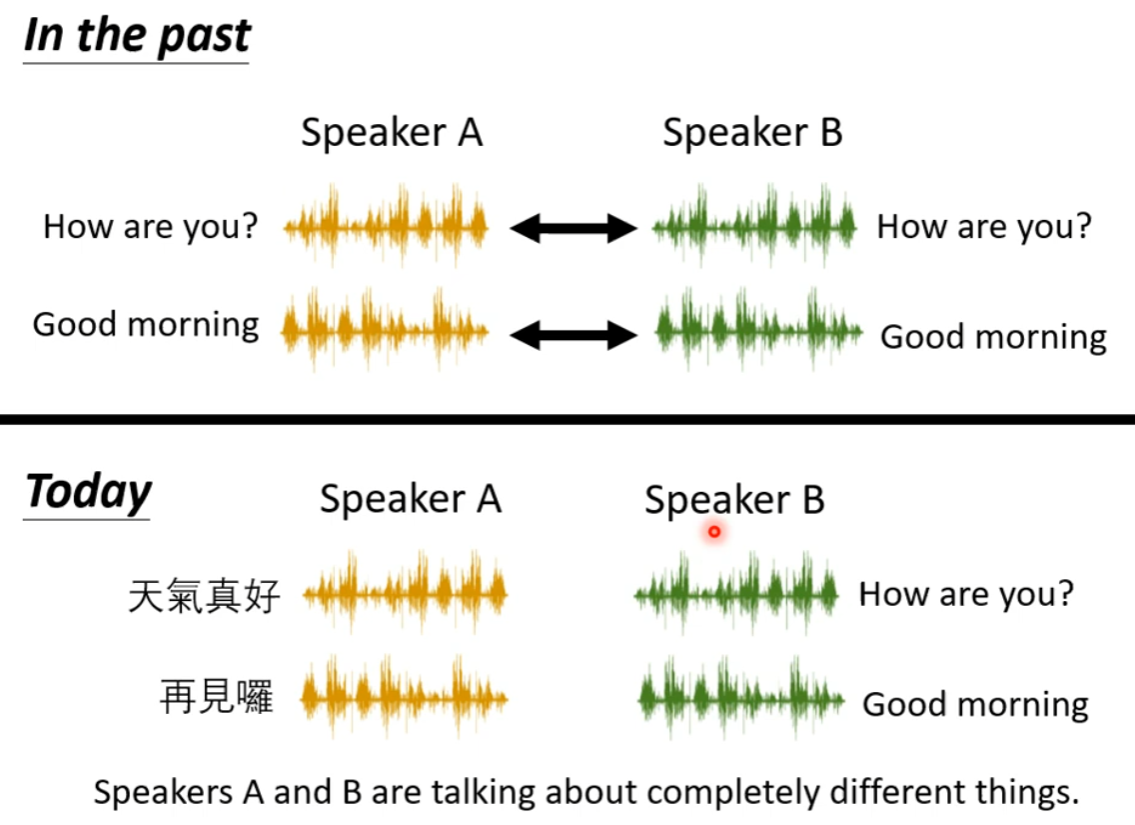
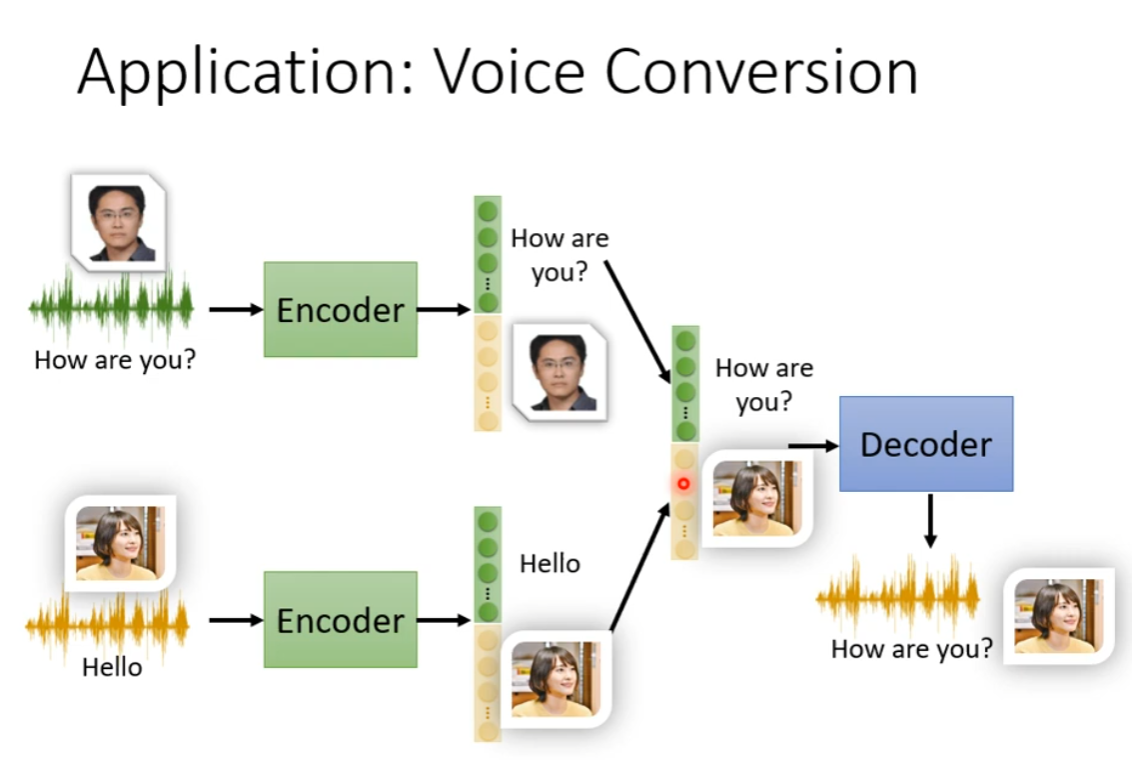
Discrete Representation
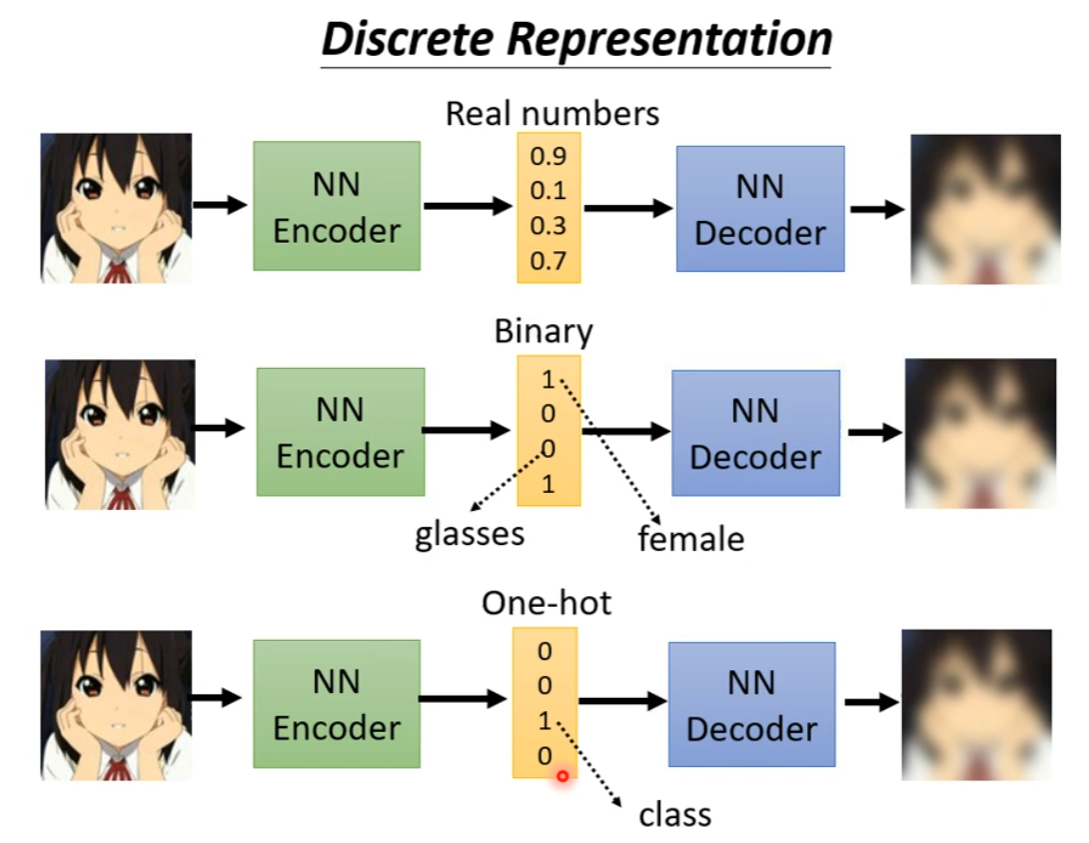
通过强制要求 Encoder 的输出为 Binary mask 从而方便分析每一维代表某一特征;或者 One-hot,从而实现 Unsupervised classification

Text as Representation
我们还可以试试把 encoder 和 decoder 都变为 Seq2Seq 的 Model,然后 embedding 不再是向量,而是一段文字,这样中间或许就是文章的精华摘要了。

但是实际行不通,因为 encoder 和 decoder 之间会发明暗号,人类无法读懂。
所以要再加入一个 Discriminator
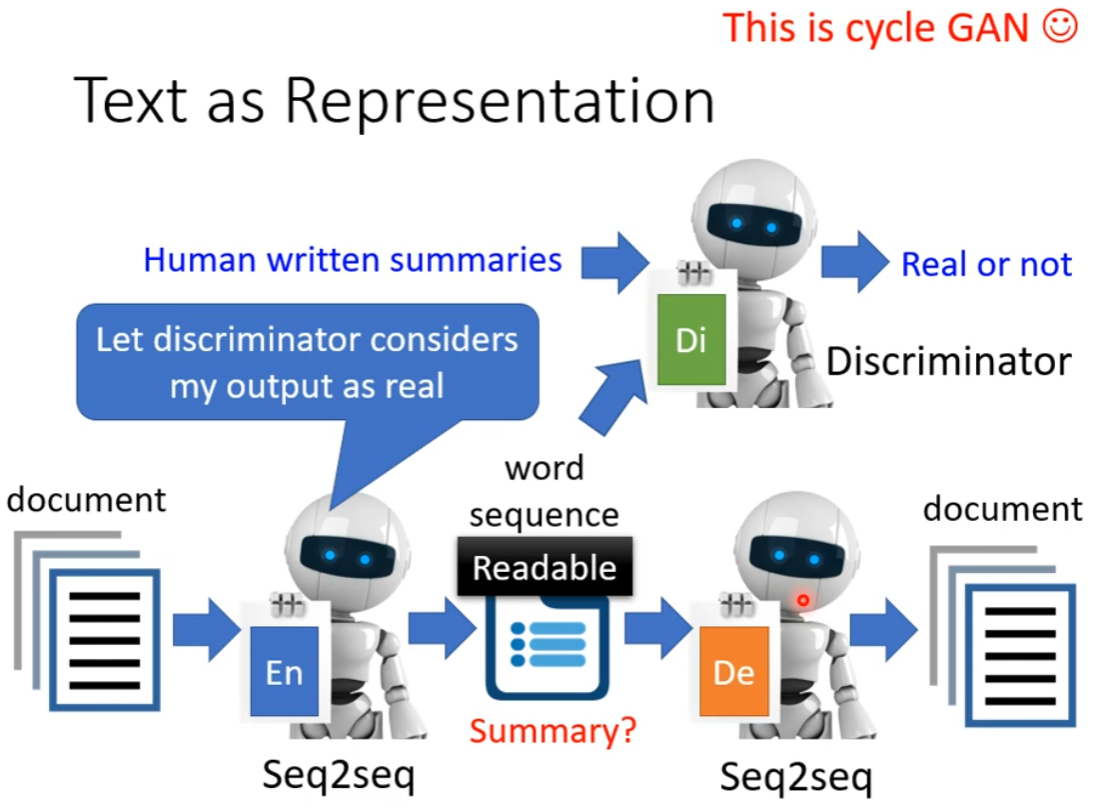
实际就是 Cycle GAN
Tree as Representation

Decoder as Generator
That is VAE
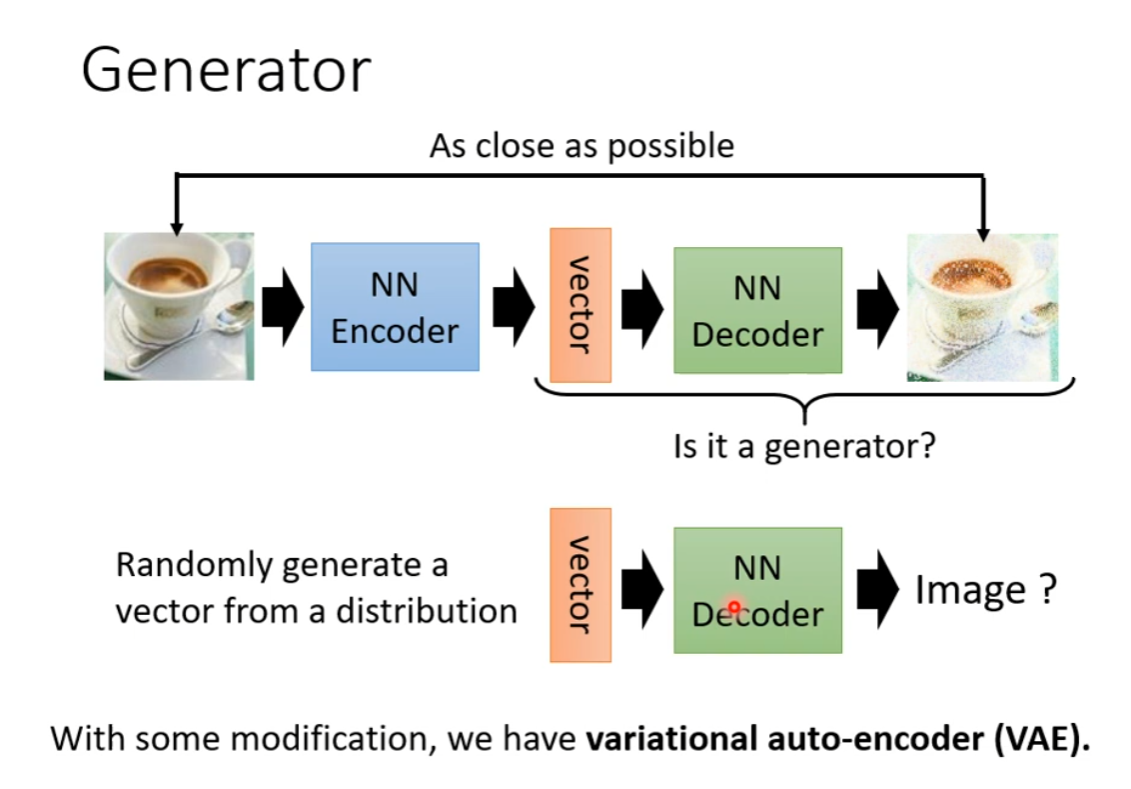
AE for Compression and Decompression
Lossy:失真

Anomaly Detection

这也称为 One-class 的分类问题。此类问题常用 AE 解决
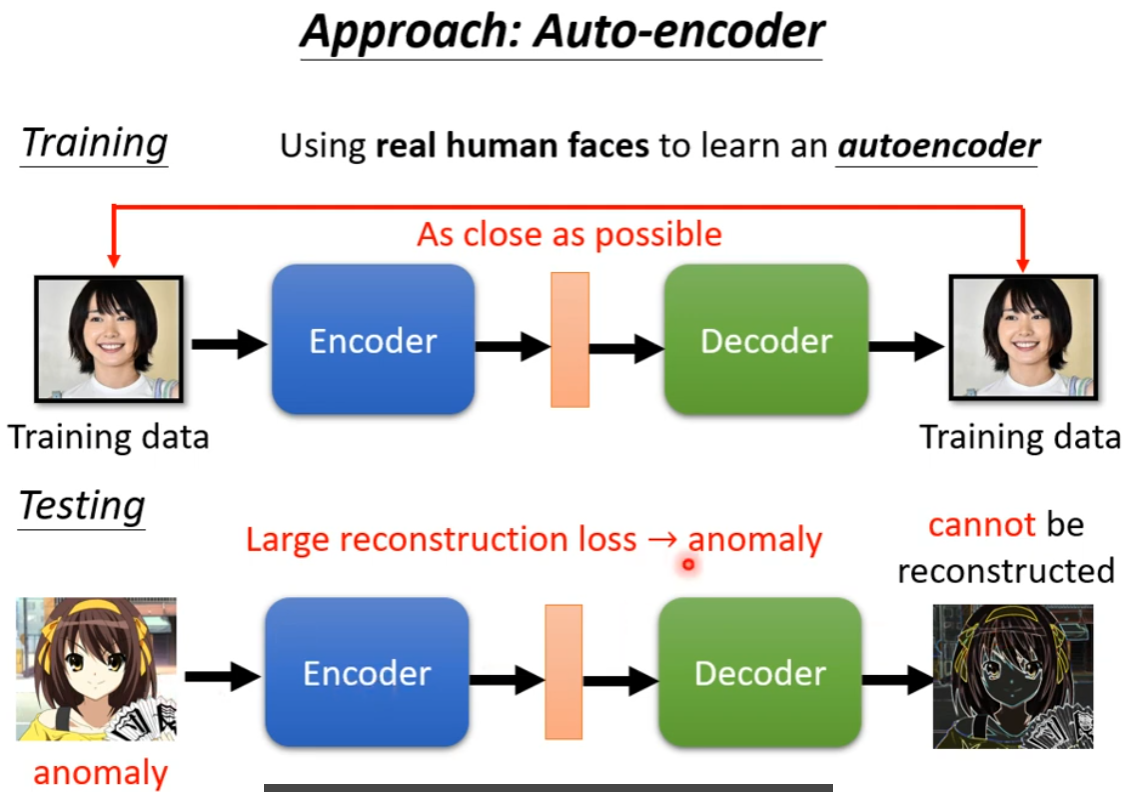
原理就是通过训练 AE,然后输入内容、重建内容。由于是用正常数据训练的模型,因此如果输入数据是正常的,就能很好的重建;而如果输入数据是异常的,由于训练时没有见过此类数据,模型不能很好的重建,失真严重,就可以被判断为是异常了。