在之前,我们见过了许多巨大的模型,例如 BERT、GPT。那么我们能不能简化这些模型,使得参数量变小的同时,也有差不多的效果呢?
Network Pruning
“树大必有枯枝”,巨大的 Network 里一定有一些参数、神经元是多余的,并没有什么贡献,因此可以剪去。

Weight or Neuron
-
Weight

以 weight 为单位进行剪枝,会导致 Network 的形状不规则,不好开发,并且也不方便 GPU 加速。如果给去掉的 weight 赋值为 0 还会导致模型实际没有变小。 -
Neuron

以 neuron 为单位剪去,可以使模型仍然规则,便于开发和加速。
Why Pruning
既然我们要把模型剪枝变小,而且这个过程中,正确率并不会掉太多,那何不直接 train 一个小的模型呢?
实际上,如果直接 train 小的模型,很难达到大模型那样的能力,也不如大模型剪枝的效果好。
有一个 Lottery Ticket Hypothesis:

也就是模型训练有随机性,而一个大模型可以视为多个小模型,只要一个训练成功了,整体就是成功的。因此大的模型就相当于买了更多的彩票,更有机会中奖。
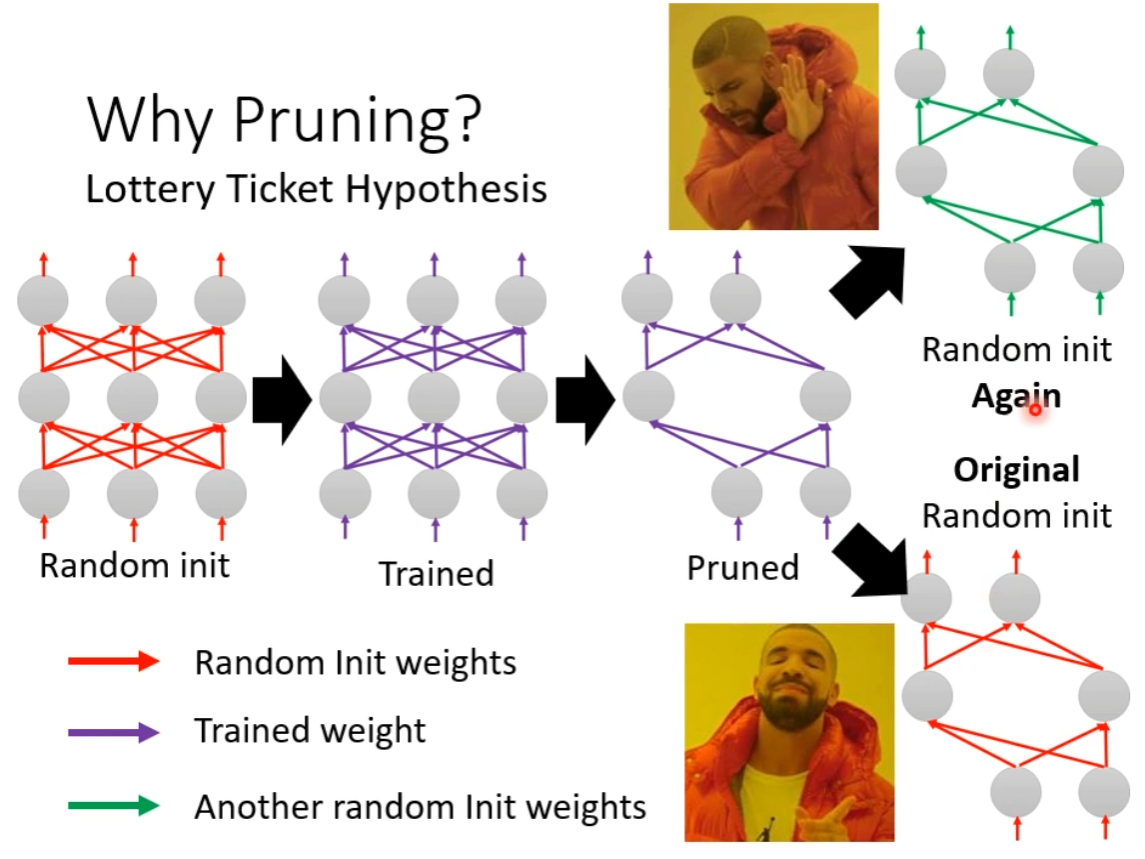
当然也有相反意见,认为是对小的 network 的训练 epoch 不足导致的:

Knowledge Distillation

好处有二:
- 直接 train 一个小的 network 效果可能没有大的好
- Teacher 可以给予 Student 额外信息,使得训练更简单。例如上例,Teacher 可以告诉 Student:1 和 7、9 比较像。比让 Student 直接学习见到这样的图形输出 1 要更简单。
Teacher 模型也不仅局限于一个模型,也可以是多个模型 Ensemble 的结果
Temperature

我们会把 Teacher 输出概率前的 latent vector 除以一个 Hyperparameter Temperature,使得分类正确性不变的前提下,概率分布更平滑。因为如前所述,Teacher 给 Student 类别相似的额外信息可以更好 train,但是如果 Teacher 表现太好,分类后概率很集中,那就和普通的 label one-hot 区别不大了。
Other Option
当然,我们也可以用 softmax 前的结果 train。甚至在模型中间,也可以用 Teacher hidden layer 的资料,对应到 Student 的某层来学习。
也可以训练中间模型,从而 Teacher → Middle → Student,逐层蒸馏训练。
Parameter Quantization

可以显著降低模型占用的空间。
乃至 Binary Weight,有时候效果会很好(可能是防止 Overfitting)

Architecture Design
Depth-wise Separable Convolution
-
Standard CNN:
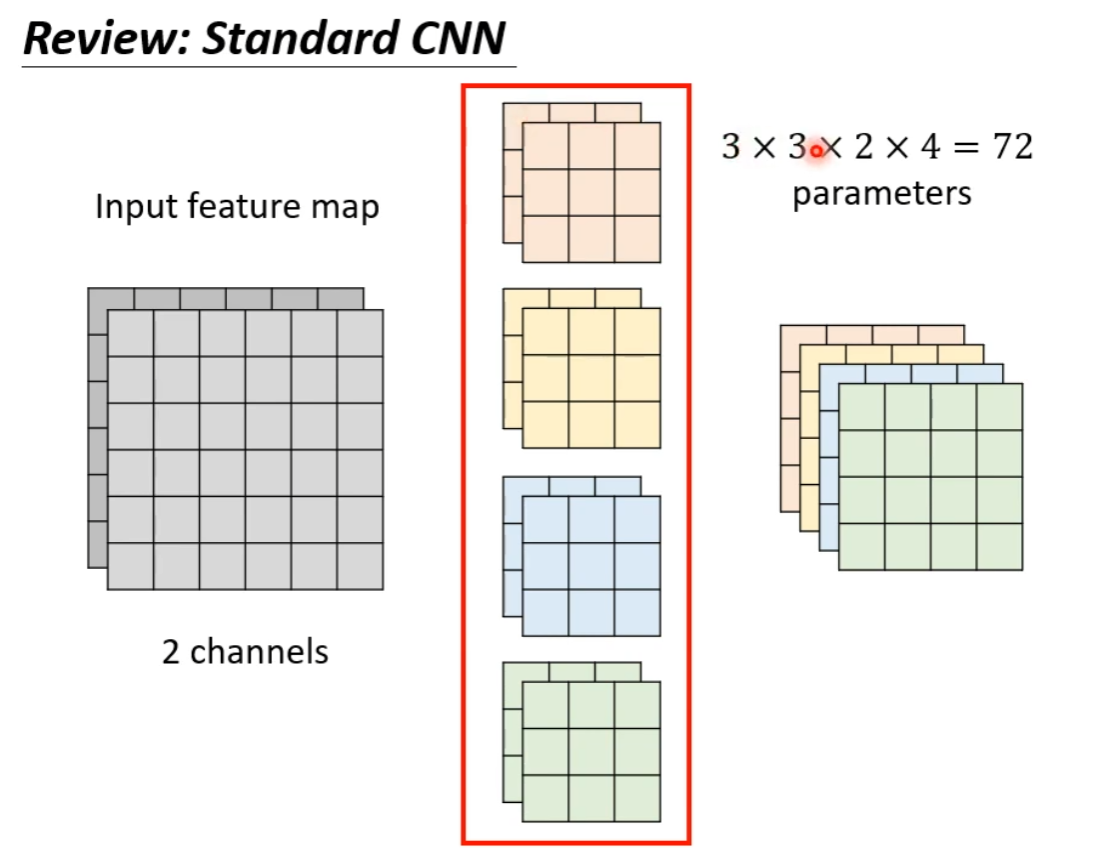
经典 CNN 的卷积核负责所有通道,是一个立方体,参数量随着 feature map 的通道数增加剧烈上升。 -
Depth-wise Separable Convolution
- Depth-wise Convolution

Feature map 几个 channel,就有几个 kernel,并且每个 kernel 只负责一个 channel。也就是只考虑 channel 内空间关系。 - Point-wise Convolution

进行 kernel size 为 1 的卷积操作,和普通的卷积一样,每个核考虑所有通道,并且对应到输出的一个 channel。也就是只考虑 channel 间关系。
- Depth-wise Convolution
参数量对比:

原理:Low Rank Approximation


也就是把一层拆成两层
Dynamic Computation
让 Network 可以自由调整其需要的运算量,因为同一个 network 想要跑在不同的 device 上;或者在同一个 device 上,根据现有资源状况调整运算量,而不需要 train 多个模型。
Dynamic Depth

Dynamic Width

Computation Based on Sample Difficulty
让模型自己根据输入的复杂程度,决定需要通过多少层的运算。
