Learn to Learn
Can machine automatically determine the hyperparameter? This is one of what meta learning dedicated to.
Introduction of Meta Learning

Meta Learning 本质上也是找一个“函数”,只不过这个函数和我们 Machine Learning 找的不一样。Machine Learning 的目的是找到可以产生我们想要的输出的函数;Meta Learning 的目的是找一个 Learning Algorithm。
但是既然本质都是找函数,那么方法也和 Deep Learning 一样,分为三步。
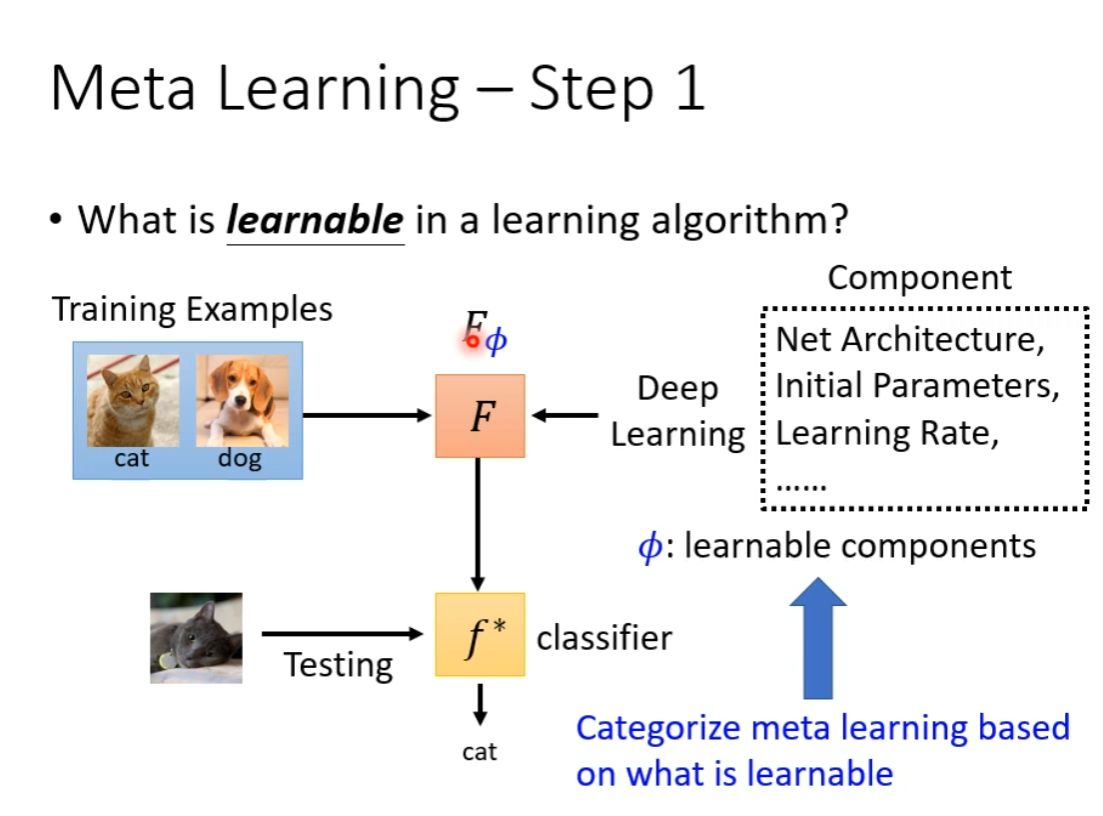
Step 1: Define Function with Unknown Parameter
正如 Deep Learning 中有可学习的参数 Weight 和 Bias,Meta Learning 也有可学习的成分,被称为 Learnable Component,在 Deep Learning 中就例如模型架构、初始参数、学习率等。
而根据那些东西被视为可学习的,区分不同的 Meta Learning。
Step 2: Define Loss Function

Meta Learning 的训练资料是“任务”,我们要为训练算法准备大量同类任务,分为训练任务和测试任务。
graph TD subgraph T1[Task 1] subgraph T1_train[Train / Support Set] T1_tr1[Sample 1] T1_tr2[Sample 2] end subgraph T1_test[Test / Query Set] T1_te1[Sample A] T1_te2[Sample B] end end subgraph T2[Task 2] subgraph T2_train[Train / Support Set] T2_tr1[Sample 1] T2_tr2[Sample 2] end subgraph T2_test[Test / Query Set] T2_te1[Sample A] T2_te2[Sample B] end end
一个任务就是我们深度学习的一个数据集,包括 Training dataset 和 Testing dataset
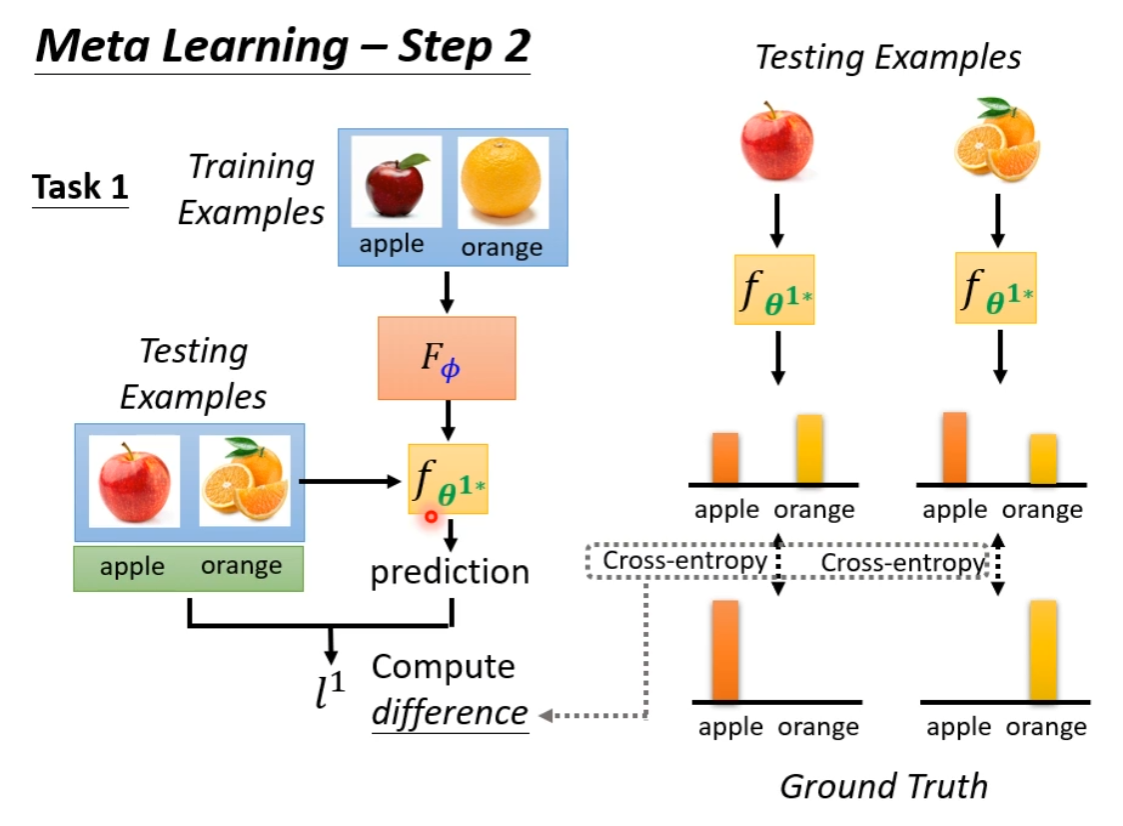
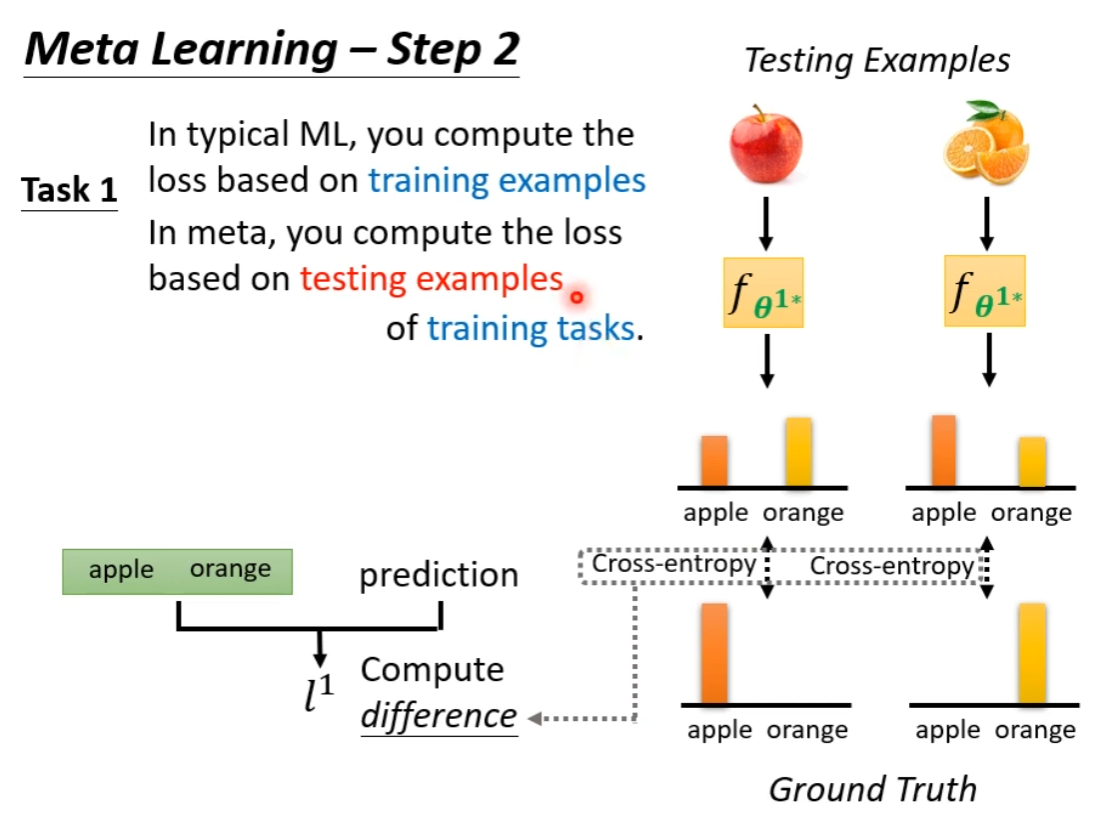
我们根据训练出来的模型好坏(实际就是训练出来的模型的 Loss)来评判训练出来的算法的好坏。
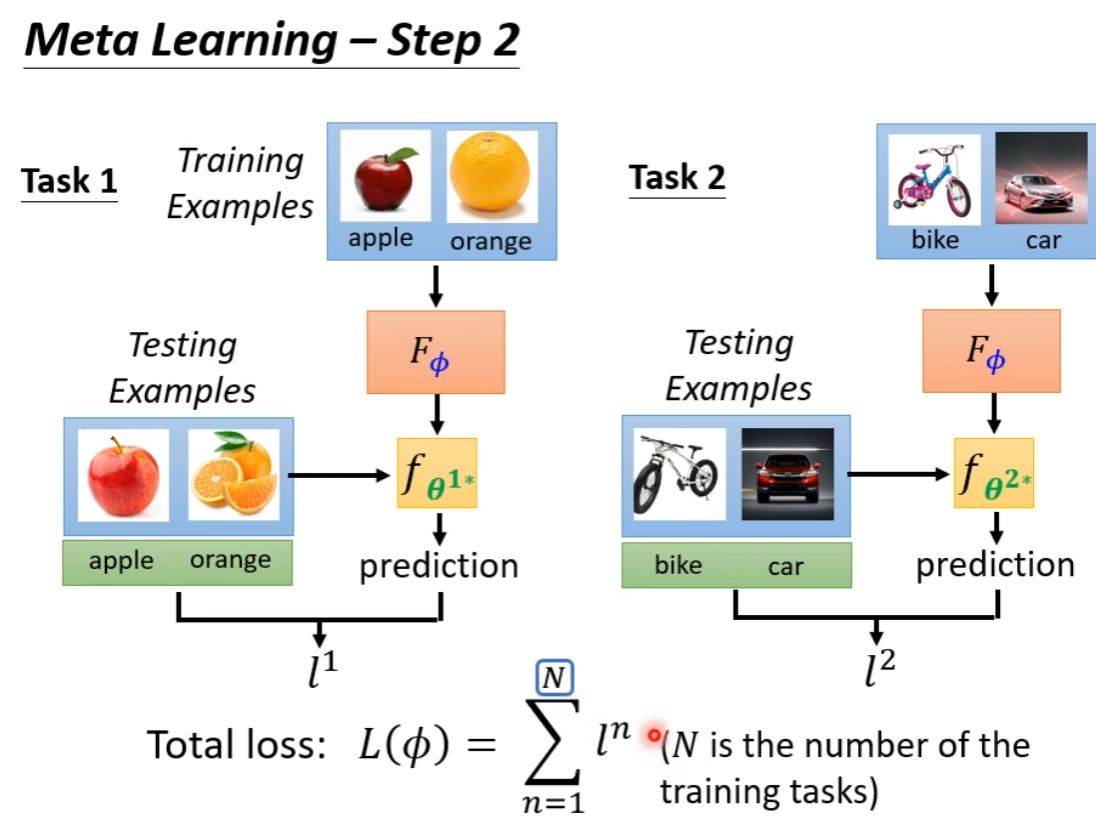
我们统计准备的所有任务下训练的模型的 Loss,加和作为我们算法的 Loss
也就是我们靠 Meta Learning 学习的 Algorithm,用 Training Tasks 的 Training Data 训练模型,并且把模型跑在 Training Tasks 的 Testing Data 上计算每个模型的 Loss,加和求出 Algorithm 的 Loss。
Optimization
所以此时,问题又变成了一个优化问题。

Framework
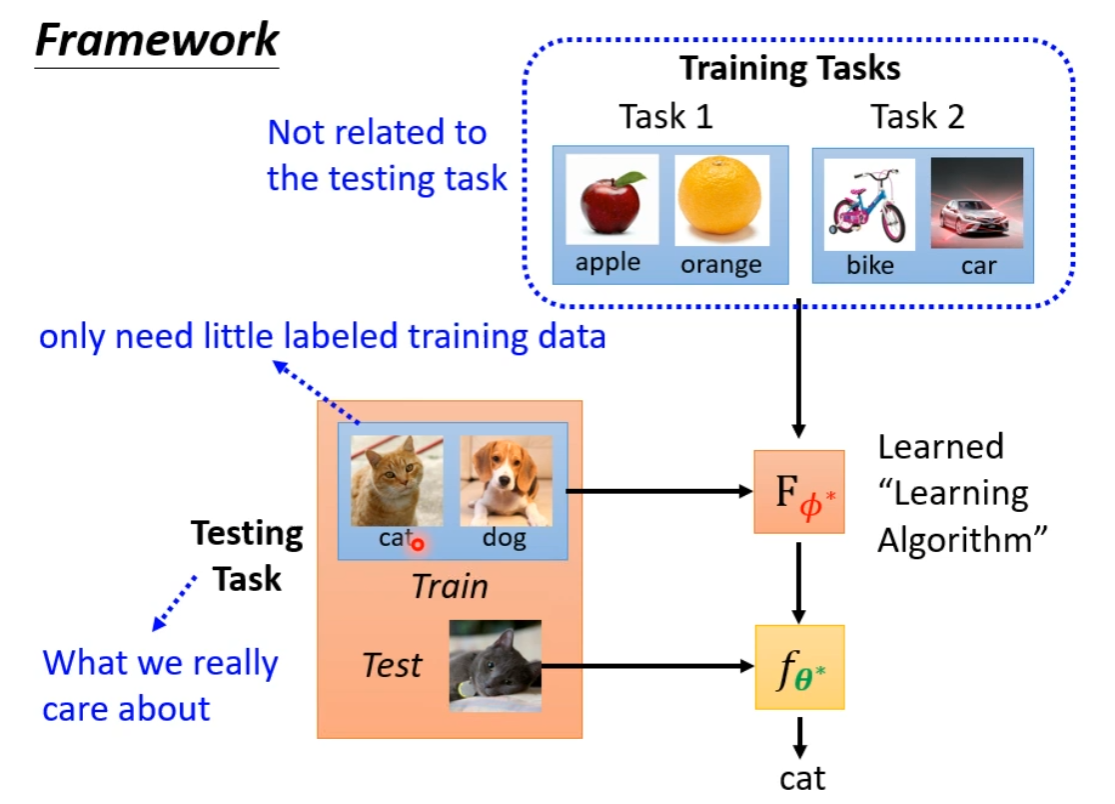
Machine Learning v.s. Meta Learning
-
Goal

-
Training Data
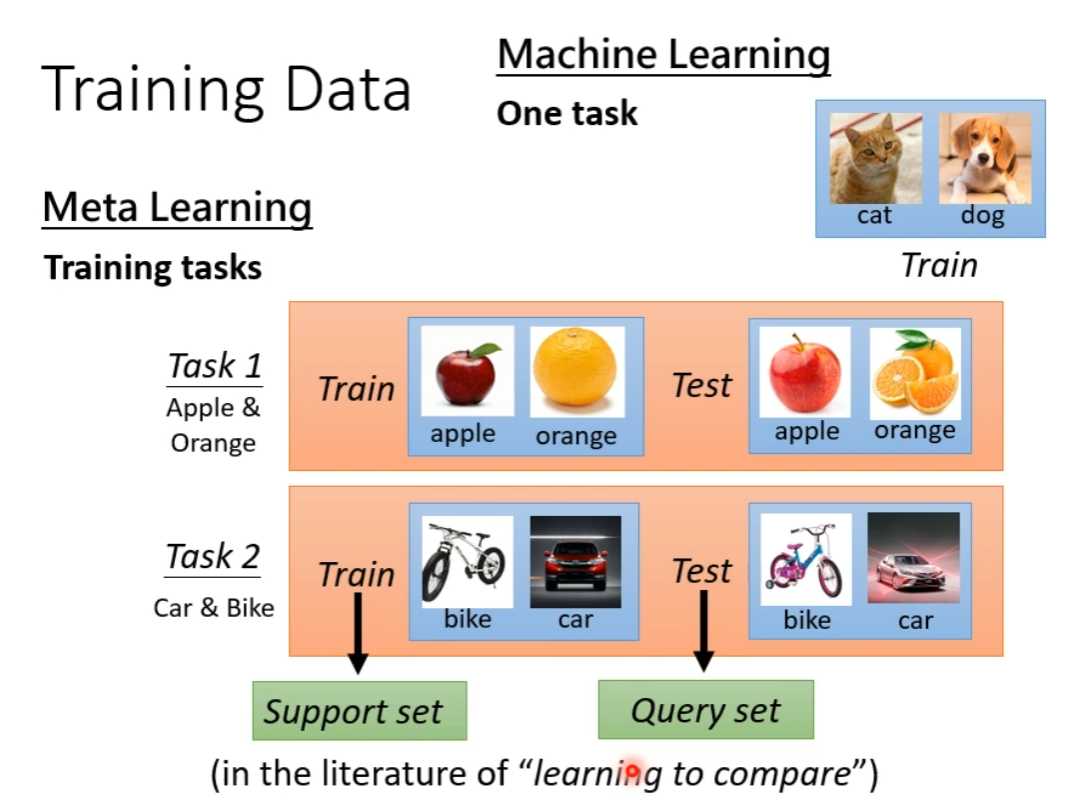
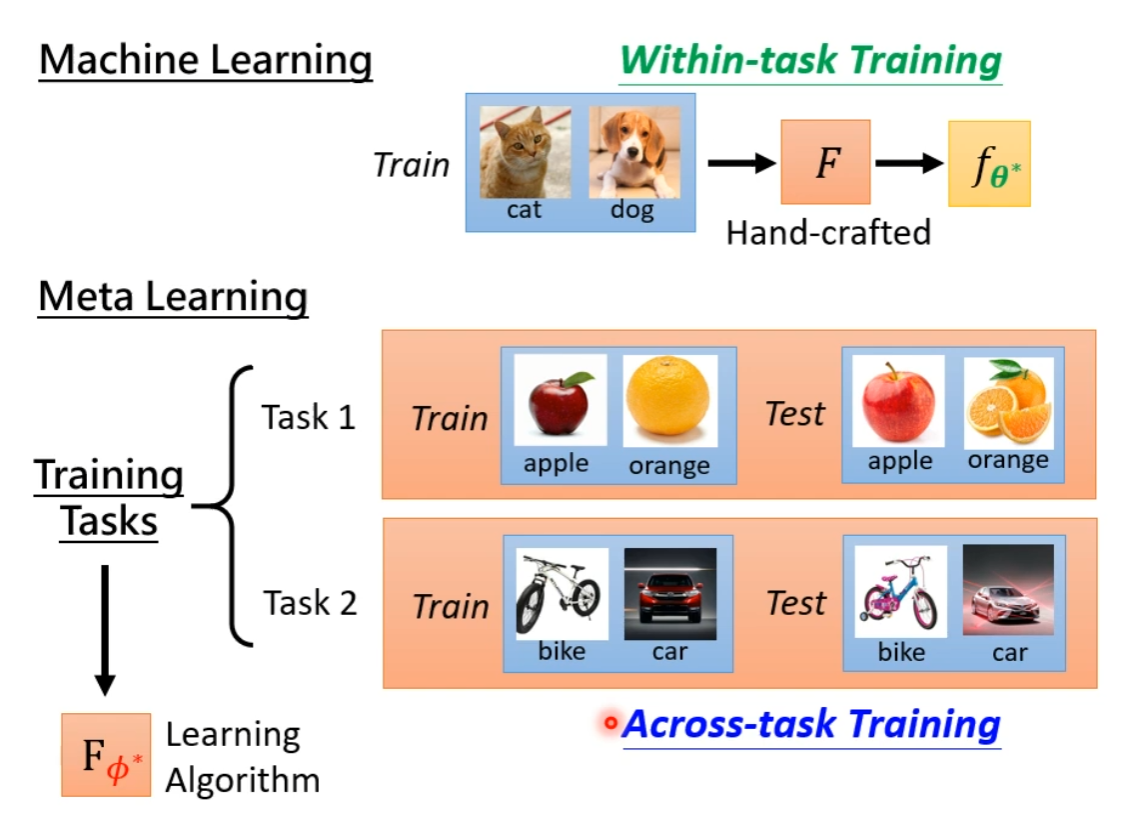
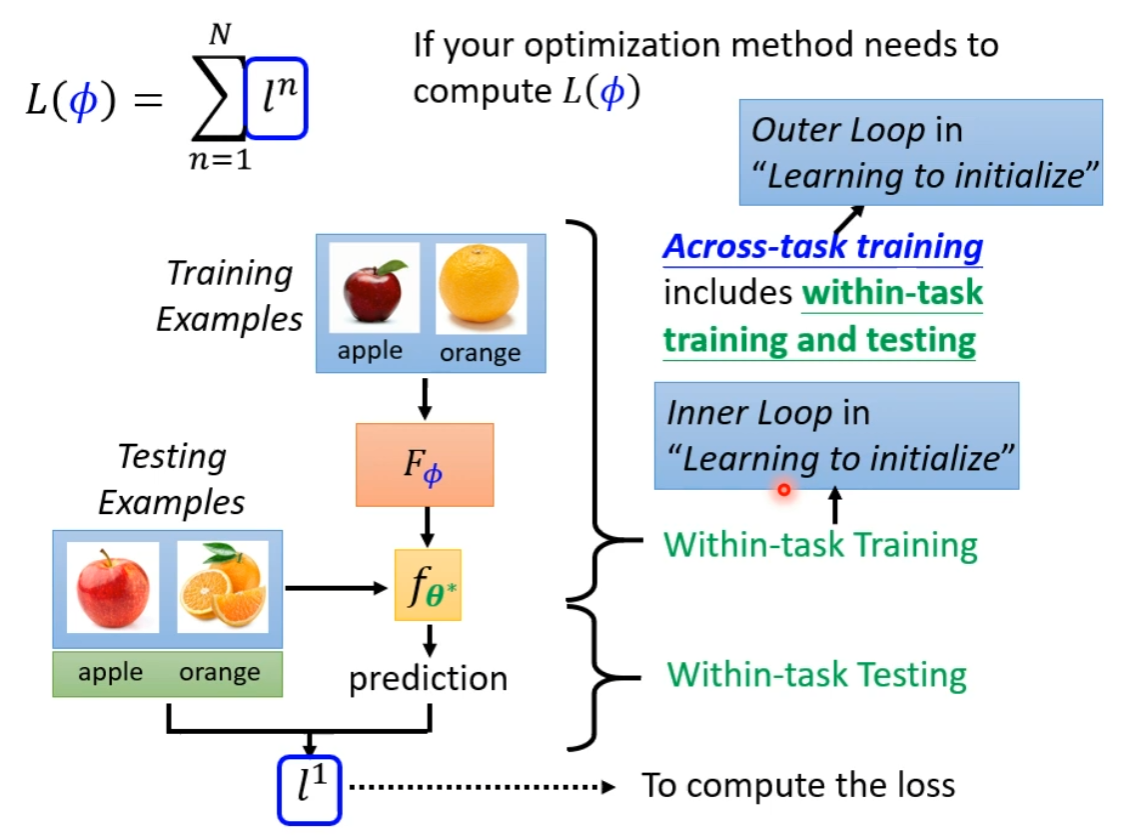
(注意区分训练一个具体模型的 Within-task Training 和训练算法的 Across-task Training ) -
Testing Data
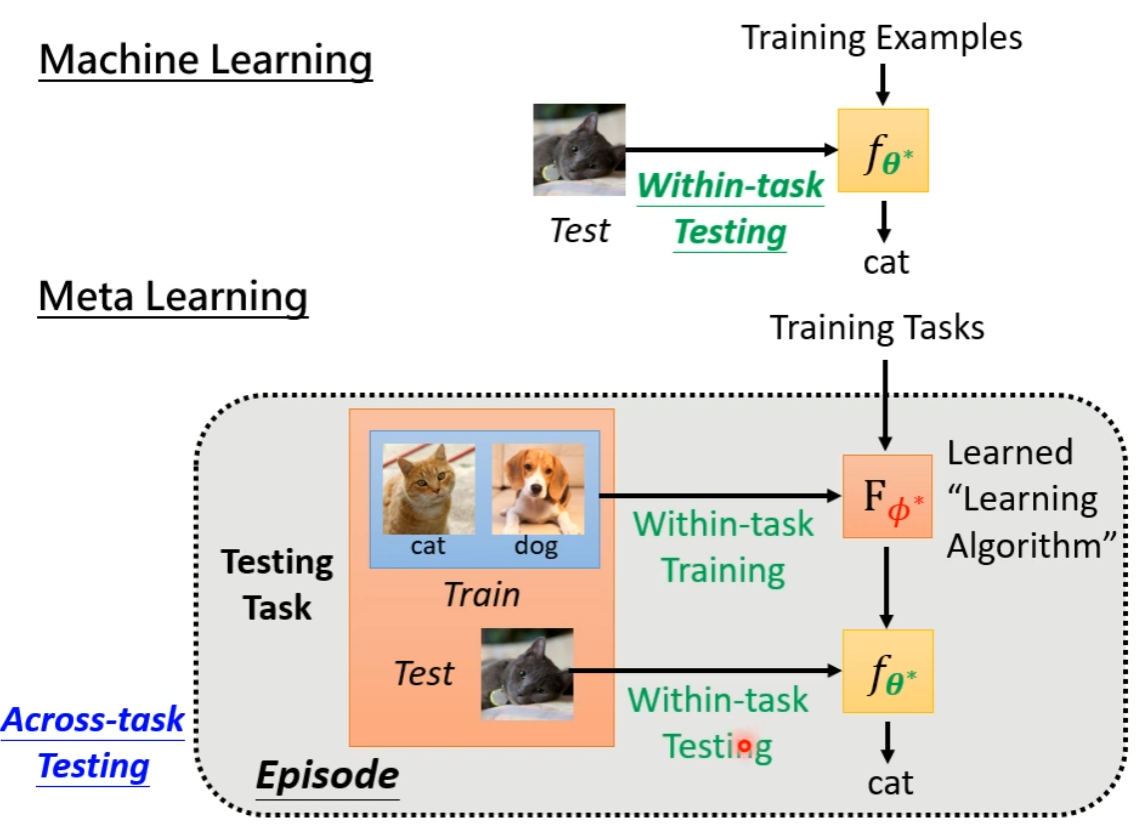
(同理划分 Within-task Testing 和 Across-task Testing。后者包含 Within-task Training 和 Within-task Testing,这两者整个流程称为一个 Episode ) -
Loss
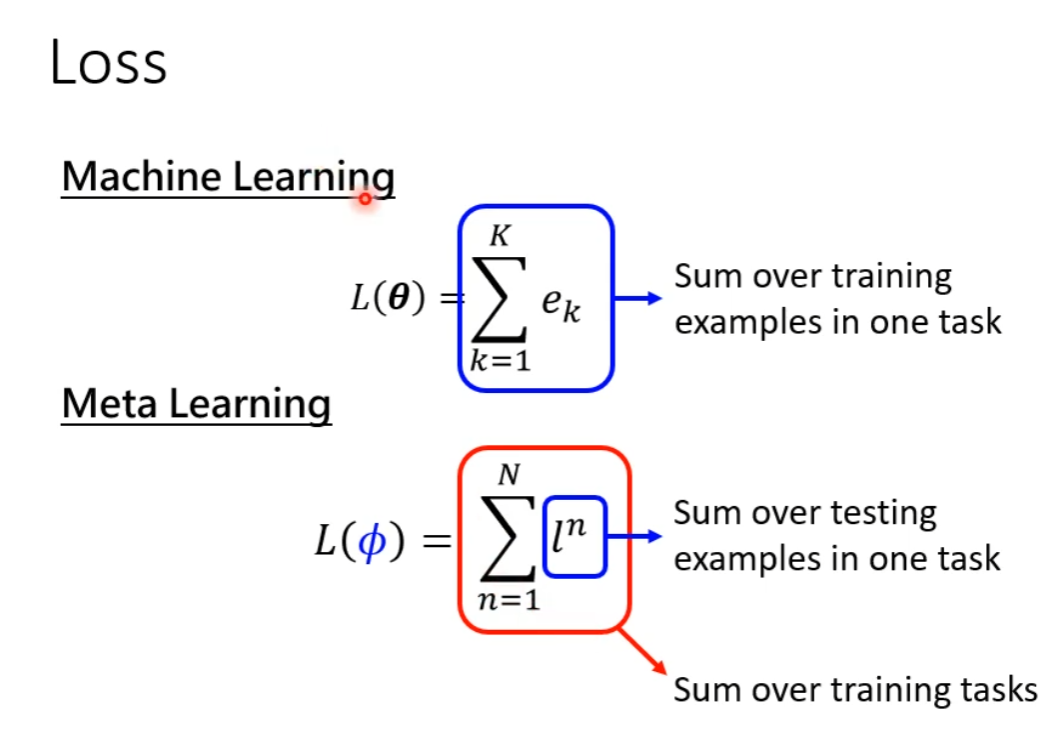
(注意 Learning to Initialize 系列文章的特别称谓)
- similarity

也就是大多数概念是通用的。
是的… 所以 Meta Learning 也要调参!不过 Meta Learning 的目的就是一劳永逸,找到好的 Algorithm,以后训练同类模型不用再调参了,并且可以做到 Few-shot
What is Learnable in Meta Learning
初始参数

注意与 Self-Supervised Learning 对比:
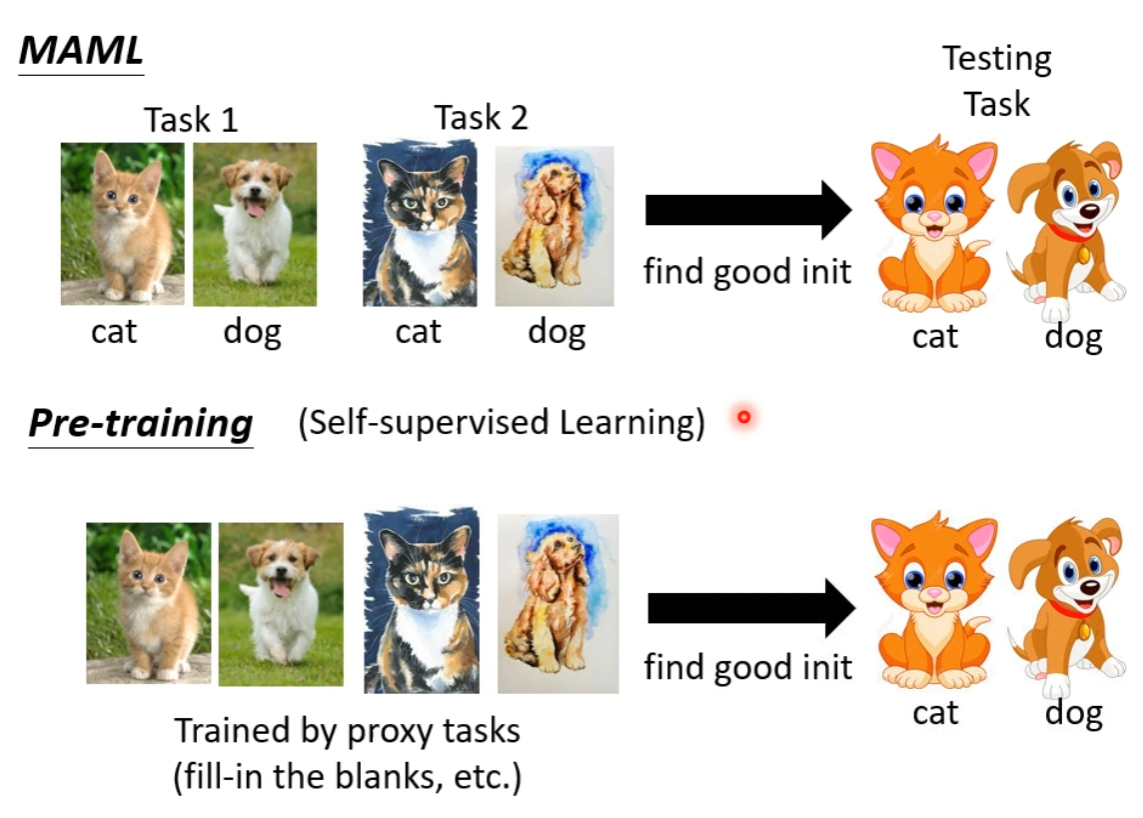
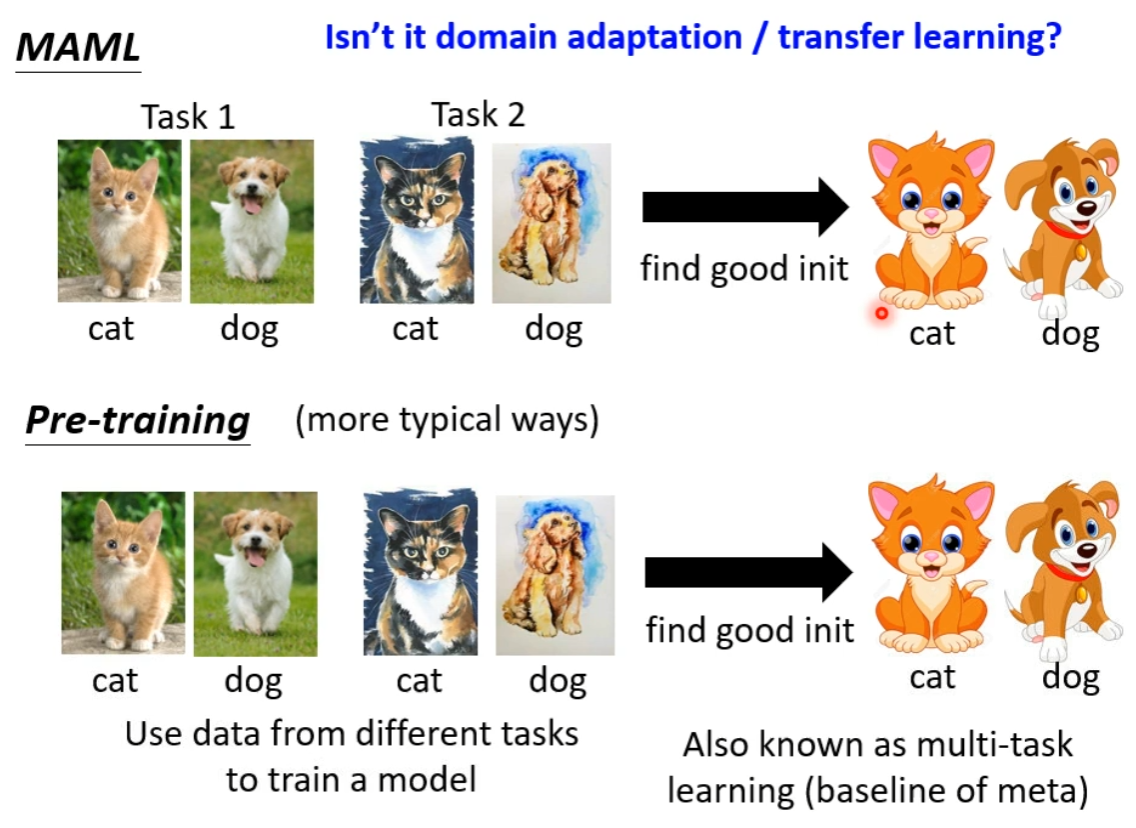
也要和一种更老的、非自监督学习的 “Pre-train” 方法( Multi-task Learning )区分:

这一种方法经常用作 Meta Learning 的 Baseline,毕竟整体上他们用到的训练数据是一样的,只是使用方法不同。
当然,如果在 Meta Learning 中,不同的 Task 只是不同的 Domain 上的同一类任务的话,也可以看作 Domain Adaptation 或 Transfer Learning
Why MAML is Good?
有两种说法:
- MAML 找到的初始参数有利于机器快速学习到各个任务的合适参数
- MAML 找到的参数和其他任务的合适参数很接近,因此可以很快学习到合适参数

该 Paper 认为是后者,即 Feature Reuse
Optimizer

Network
Network Architecture Search (NAS)
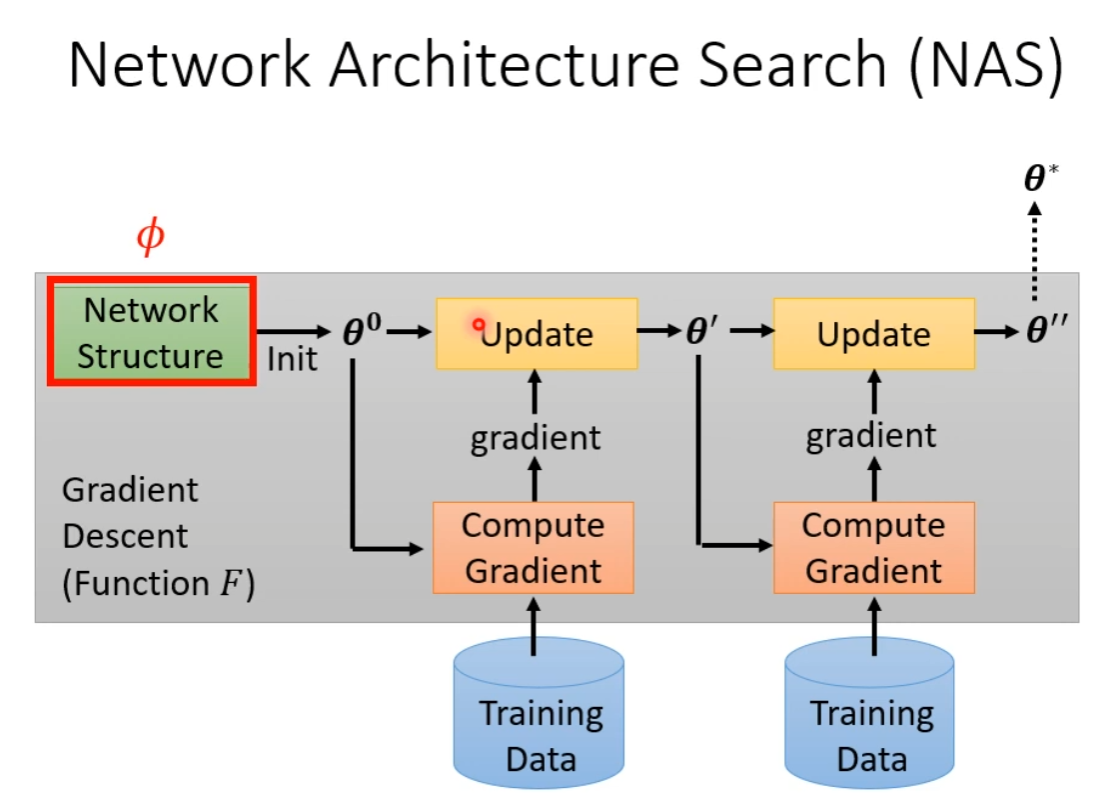
当然,无法对架构进行微分,因此不能梯度下降了,要用 RL 做。

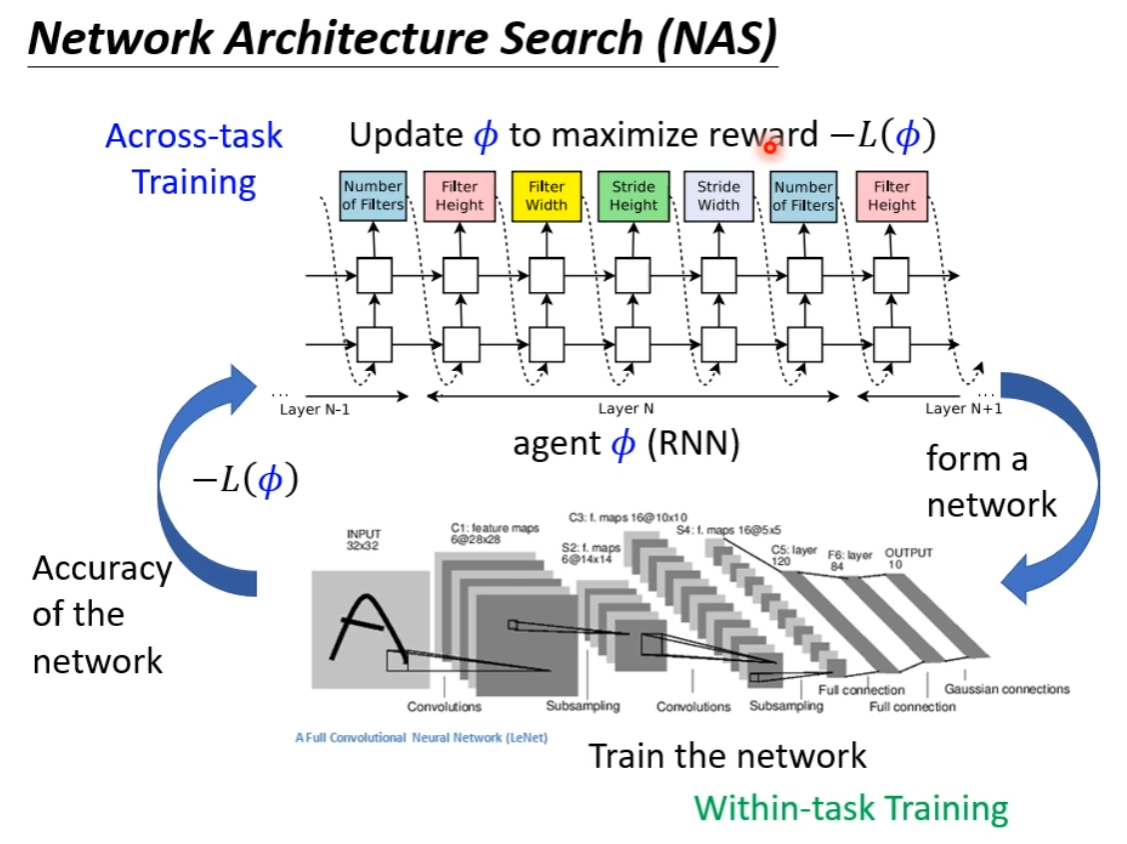
或者用 Evolution Algorithm

又或者把 Network Architecture 改一下,变得可以微分(DARTS)

Data Processing
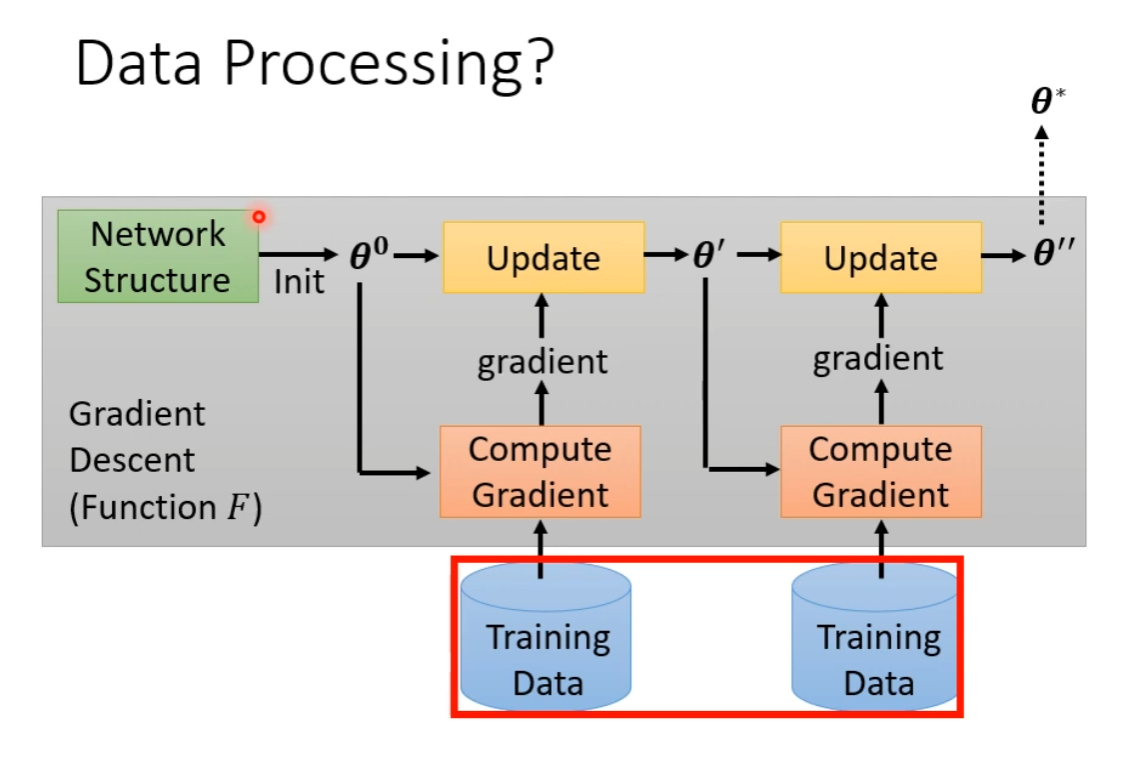
-
Data Augmentation

-
Sample Reweighting

Beyond Gradient Descend


Application
Few-shot Image Classification

常用 Omniglot 作为 corpus
