Domain Adaptation
假设测试资料和训练资料的分布不一样怎么办?
Domain shift: Training and testing data have different distribution
那就需要用到 Domain Adaptation 的技术,这项技术可以视为 Transfer Learning 的一种。
可能的情况

- 输入资料的分布不同:上例,训练为黑白,测试为彩色
- 模型输出的分布不同:上例,训练的输出概率比较平均,测试的输出概率集中于 1。
- 输入输出的对应关系不同:上例,训练集中此种图形对应 0,测试集中此种图形对应 1。
我们下文专注于输入资料分布不同的 Domain Shift 上,称 Training Data 的来源为 Source Domain,Testing Data 的来源为 Target Domain
应对方法
根据我们对 Target Domain 的了解不同,我们可以采用的最好方法不同
Little but Labeled Data

为了防止 Overfitting,fine-tune 环节只需要几个 epoch 就好,然后还可以通过降低 learning rate,限制 fine-tune 对模型参数的改变等方法进一步降低风险。
Large but Unlabeled Data
常常在真实世界中发生的场景
Basic Idea

也就是找出一个 Feature Extractor 的 Network,用来提取 Source 和 Target 中共同的特征,过滤掉不同的地方,使得两者有同样的分布,然后用在 Source Domain 提取的特征训练模型,可以直接用在 Target Domain 上。
Domain Adversarial Training
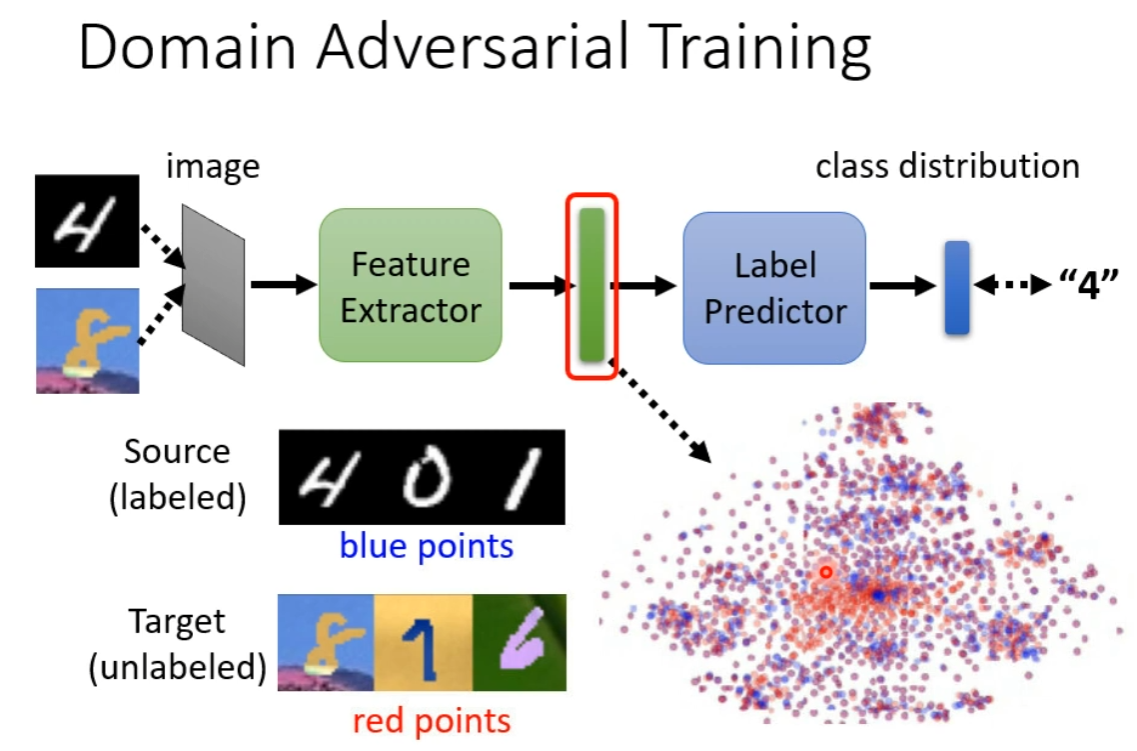
针对我们的分类模型,我们将其分为两部分,前 层为 Feature Extractor,后 层为 Label Predictor(如何划分也属于一个 hyperparameter)
然后针对 Feature Extractor 的输出,我们期待:Source 和 Target 的输入进去后产生的 Feature 要有相同的分布。
如何做到呢?Adversarial!非常像是 GAN(Generative Adversarial Network) 的思路。

由于 P 要用到这个 Feature,所以 F 也不能做到摆烂输出全零。因此 F 的任务就是,一边欺骗 D,一边提取合格的特征,供给 P 正确分类。
并且 前一般有一个系数 ,经常进行 schedule,例如:
但是,这里有个微妙的地方:
D 的任务是正确分开来自 Source 和 Target 的数据,而我们在 F 的 Loss 处加上负的 D 的 Loss,那意味着 F 做的事要和 D 相反,让 D 把来自 Target 的数据认为是来自 Source 的,把来自 Source 的数据认为是 Target 的。如果这样,不也是把两组的 Feature 的分布给分开了吗?而不是让他们没有差别。
所以这样做尽管有用,但是还有更好的方法。
Limitation
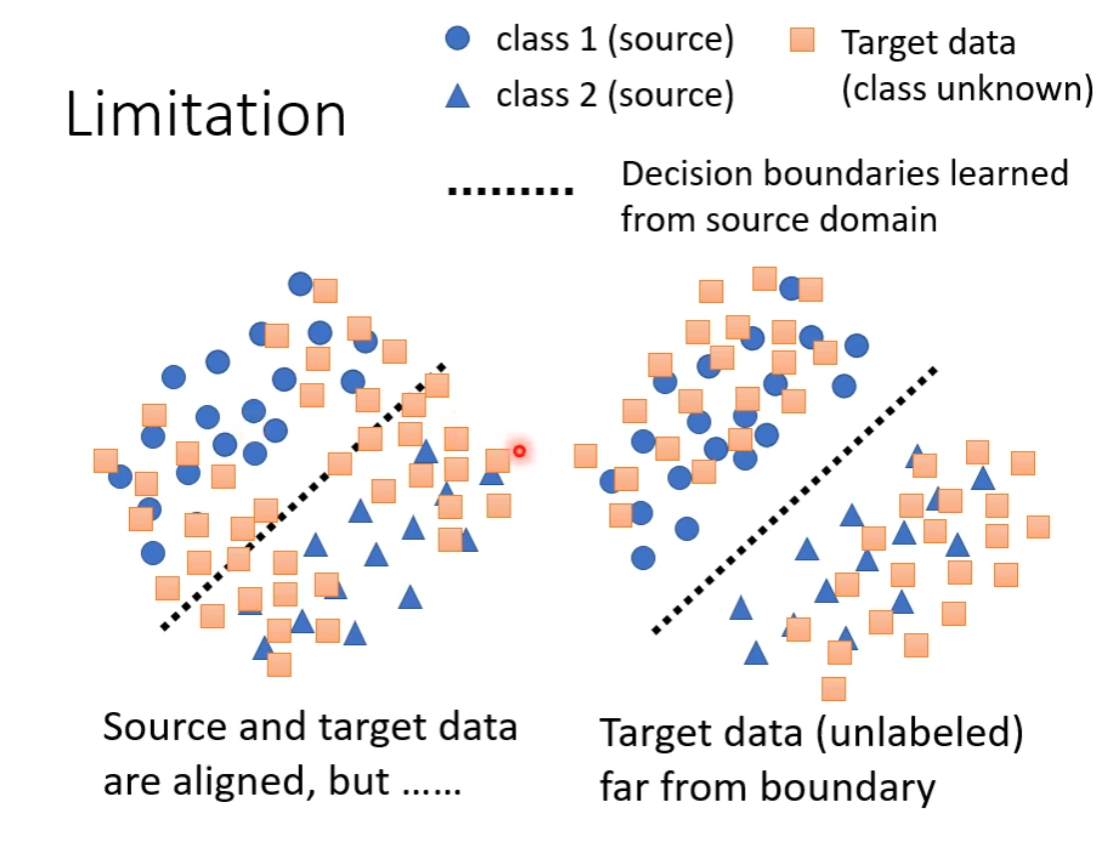
由于我们并不知道来自 Target 的数据的分类,所以有时候虽然 Distribution 以及 Align 上了,但是不一定很好的能由模型学习到的 Boundary 分开。而右边显然是更好的,不但做到 Align,还让 Target 分布远离了 Boundary
解决方法:

有很多啦,简单的例如控制分类的 Entropy,虽然不知道数据是什么类别的,但是要求他的概率集中在某一个类别上
可以这样实现:(注意和 Cross Entropy 的区别,这里没有真实标签)
target_logits = label_predictor(feature[source_data.shape[0]:])
target_probs = F.softmax(target_logits, dim=1)
entropy_loss = -torch.mean(torch.sum(target_probs * torch.log(target_probs + 1e-6), dim=1))
loss = class_loss + lamb * domain_loss + 0.1 * entropy_lossOutlook
我们刚刚都在假设,SD 和 TD 中的类别是一样的,但这是不一定的。所以强行把他们的 Distribution Align 在一起,可能有一些问题。

Little and Unlabeled
Know Nothing - Domain Generalization
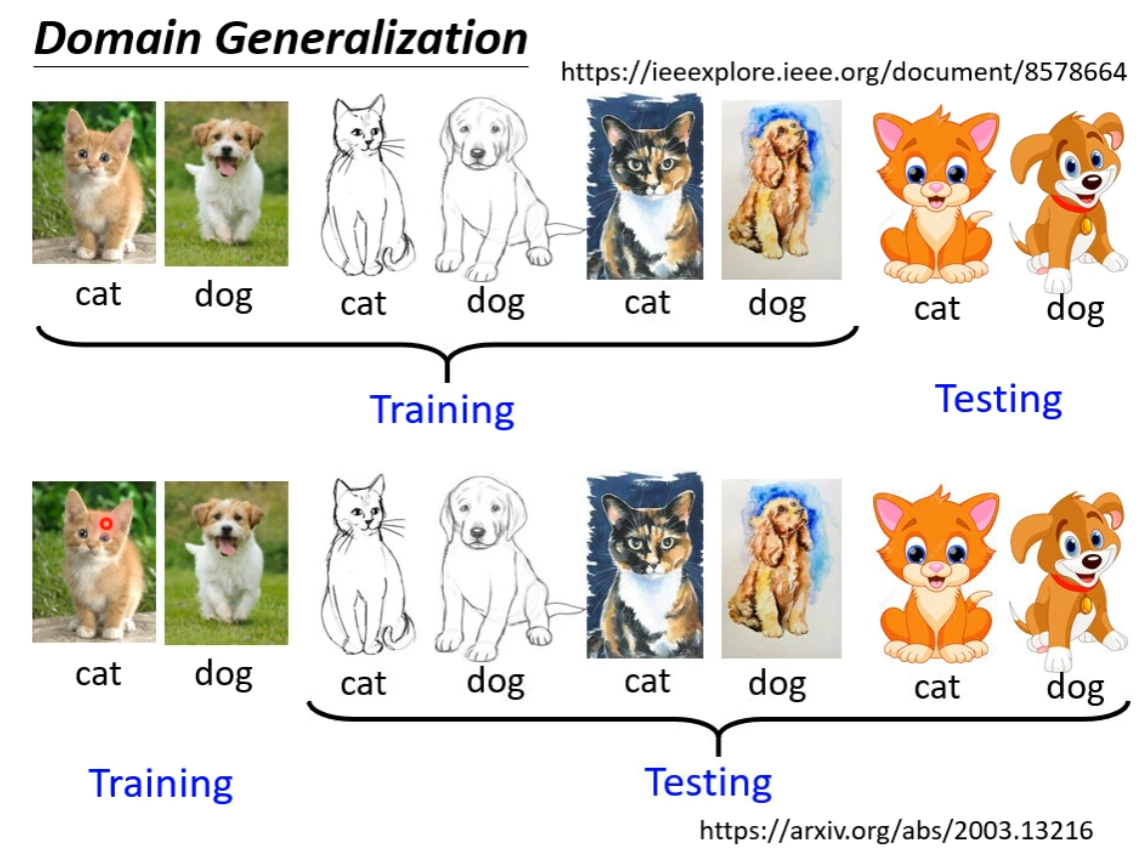
两种情况:
- 丰富的训练资料,让模型可以学会如何弥合不同类型的数据的差异
- 单一的训练资料… 方法类似于 Augmentation