What is Anomaly Detection

这个难以用二分类做到,因为我们有大量的正常资料;但是几乎没有多少异常资料,并且混杂在正常资料中, 人难以侦测,大多数时候也没有标注。并且异常可能有很多种,往往都是与正常数据不同的判定为异常,所以我们无法收集到所有类别的异常数据,更无法预测可能有什么样的异常。
可以用作:
- Fraud Detection
- Network Intrusion Detection
- Cancer Detection
Categories

With Labels: Open-set Recognition
本质上是一个 Classification 的模型,利用有标注的数据进行分类。但是会额外输出一个 Confidence来判断这个是不是有在训练集见过的,而不是强行分类的未见类型。


或者用 Negative Entropy 作为 Confidence 之类的。
甚至我们可以训练一个会 output Confidence 的 Classifier,而不是强行人指定一个 Confidence 的计算方法。
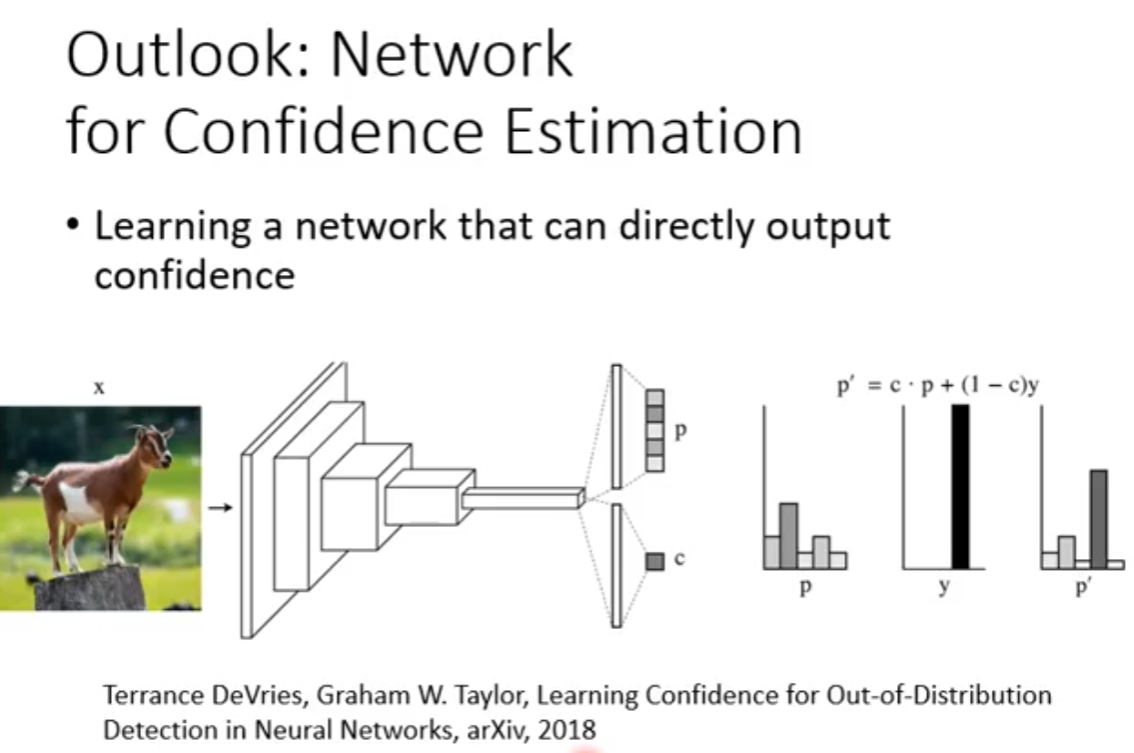
Example Framework

Evaluation

根据某阈值下,可能犯的两类错误,以及不同错误的严重程度来打分。或者 ROC 一类不考虑阈值的评估方法
Possible Issues

有一些异常资料,可能一些类似正常资料的特征十分突出,导致机器十分确信(高 Confidence)他属于某一类,从而被当作正常。
怎么办?

训练模型的时候,除去练习分类外,还用一些异常数据,训练模型看见异常的给低 Confidence
没有异常数据,或者太少怎么办?人工生成一些。
Without Labels
这时候不再可以训练 Classifier 了。

我们可以使用概率来分析,计算某一样本 sample 到的的概率多大

使用最大似然法:


计算出期望和协方差矩阵:

然后划分阈值

维度没有局限,可以加入所有可能影响判断的因素:
