Why RL
有时候,我们面对的问题无法 Label(也无法通过 Self-Supervised Learning 的方法让机器自己用输出的一部分作为 label)。也就是我们并不知道答案是什么,这时候我们需要用到 RL。
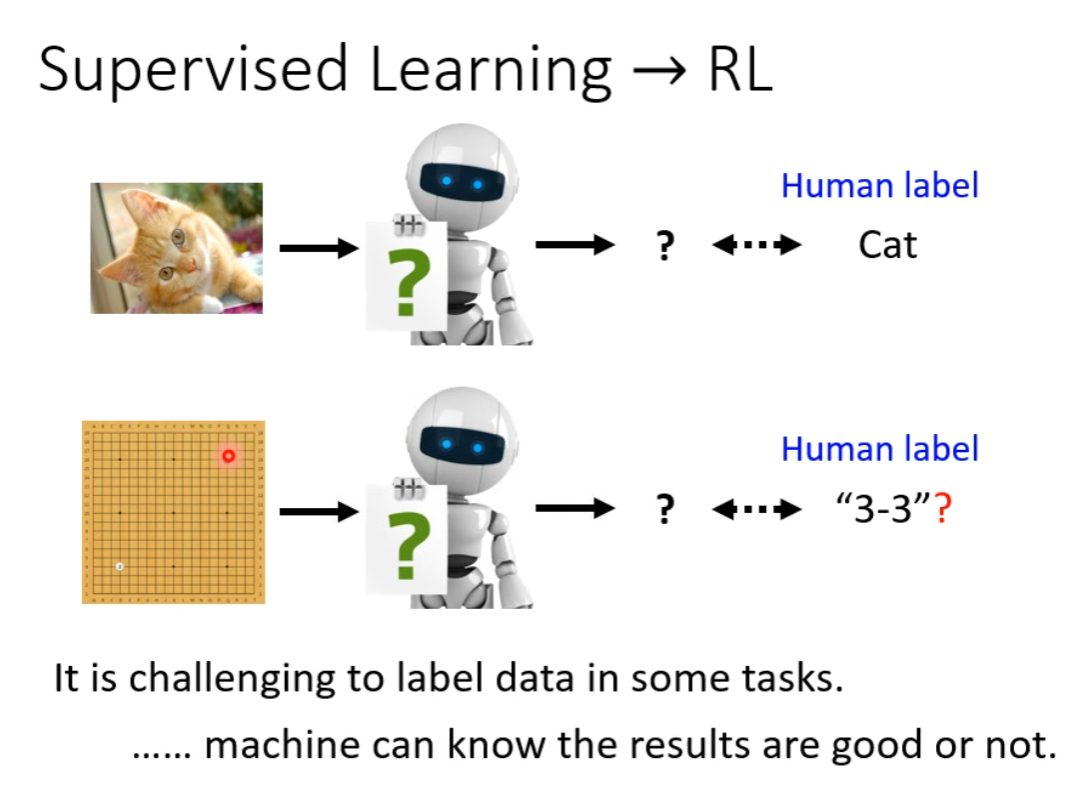
例如下围棋,我们并不知道某个局势下的最优解是什么,而机器可以知道什么是好,什么是不好。
What is RL

本质上,RL 也是在找一个函数,和 DL 一样。
我们的 Actor 接受 Environment 的 Observation 作为输入,输出一个 Action,Action 会改变 Environment 的状态,进而发出不同的 Observation 给 Actor,使得 Actor 采取下一个 Action。这就是模型的运行过程。
Example
以下用 Space Invaders 举例

过程:


Procedures
RL 的步骤,本质和 DL 也是一样的。

Step 1:Funtion with Unknown

P.s. 早期没有结合 DL 的 RL, Actor 可能是 Look-up Table 之类的。
机器采取的行为是根据概率采样,而不是直接取最大值的行为,因此可以有一定随机性,就算面临同样的场景也会有不同的反应。
Step 2:Define “Loss”

经过 ~ 多个回合后,游戏结束,称为一个 Episode,而每个回合获得 reward 分别为 ~ ,求和即为 return,也就是我们的最大化目标。
Step 3:Optimization
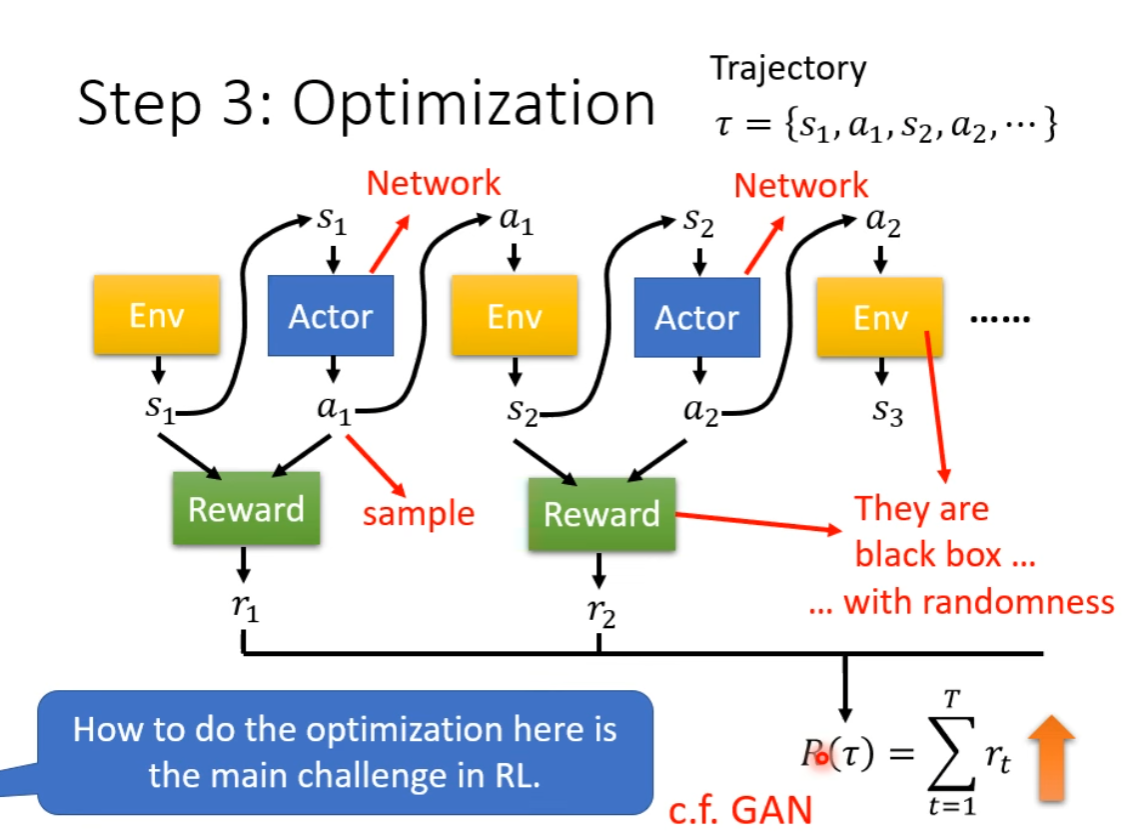
这就类似于一个 Network 的训练了,通过调整 Actor 这个 Network,最大化 Return。
但是有一个关键差异:这个网络中有很多随机性。同样的输入,Actor 产生的行为、对 Environment 的影响、Environment 给出的 Observation、对应产生的 Reward,都有一定的随机性。并且 Environment 和 Reward 并不是一个 Network,是有规则的黑箱。这也是 RL 的最大挑战。
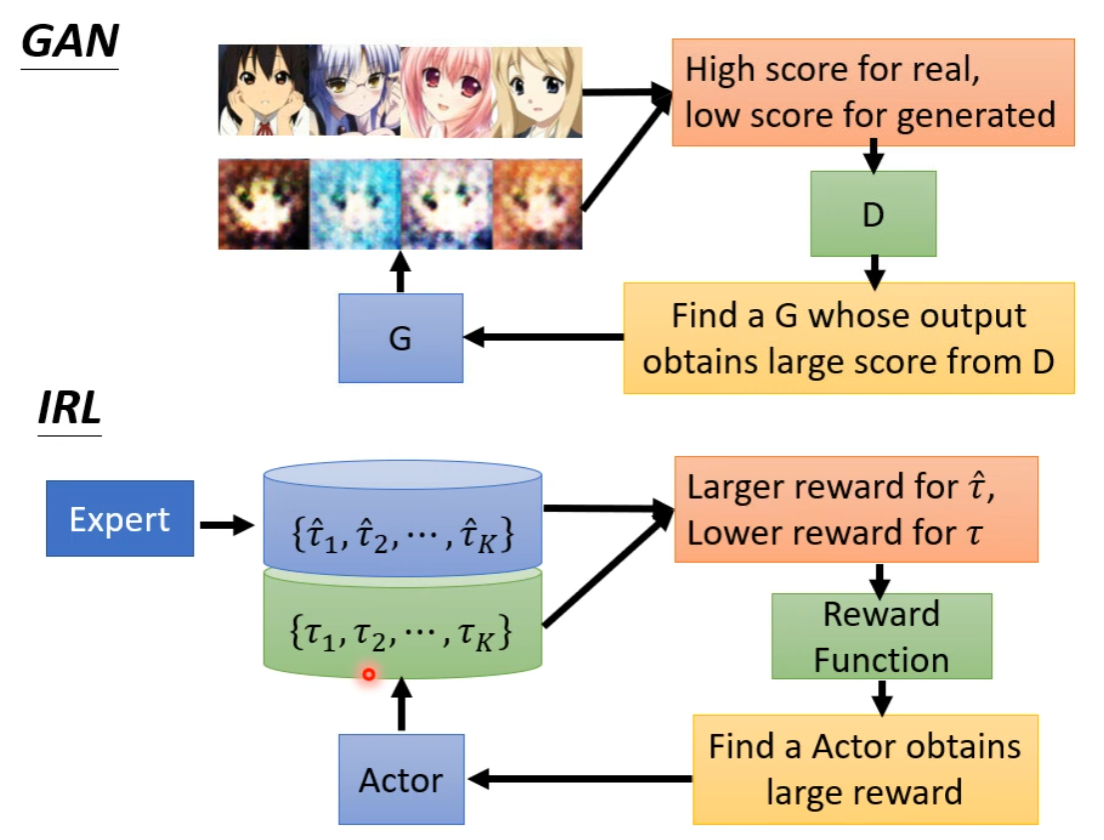
但是这个和 GAN(Generative Adversarial Network) 有异曲同工之妙:
- 相同处:我们可以把 Actor 视为 Generator,把 Environment 和 Reward 视为 Discriminator,我们要 train Generator,最大化 Discriminator 的输出。
- 不同处:GAN 的 Discriminator 也是一个 Network,可以用 Gradient Descend 训练 Generator,使得 Discriminator 得到最大输出。而 RL 中,Environment 和 Reward 是黑盒子,不是真正的 Network,无法用 Gradient Descend 的方法来调整参数。
Policy Gradient
How to Control Actor

给出适当的 Label 和适当的 Loss

因此就类似一个 Classifier 的训练

利用数据集和 label,以及我们期待或不期待他做出该种行为,规定 Loss,进行训练
甚至更进一步,我们不止给出行为的好坏,更给出好坏的程度。

问题就在于,我们如何收集成对的 Observation 和 Action,以及他们的评分呢?
How to Collect Data
Version 0

把每一步的 reward 当作打分 A,比较 “贪心” ,因此不太好,因为:
- 每一个行为会影响到后面的状态。
- 有 reward delay,可能要牺牲短期利益换取更大利益。
Version 1

使用 cumulated reward 评估行为的好坏,使得模型不再那么短视。
但是也有一个问题:假如 episode 非常长,我们把距离很遥远的 归功于 就不再合适了。
Version 2
因此稍作修正,乘上 (Discount factor):

距离越远的 reward 对当前的 action 的影响就越小。
Version 3
我们需要对 G 进行标准化,因为有时候,我们可能永远都是拿到的正的 reward,这时候小的 reward 对应的实质上就是糟糕的行为。

简单的,我们可以减去一个 (baseline),b 合理的设法是设置为 Value Function 的输出。
Policy Gradient

不同的 RL,很多都是修改 A 的计算方式等。
而可见 RL 和一般的 DL 最大不同就是,我们是在每一轮训练中收集资料。

我们收集资料、更新参数一次、重新收集资料、更新参数……
On-Policy vs Off-Policy

我们刚刚所说的就是 On-Policy 的训练,而也有对于 Off-Policy 的研究,因为后者可以不必在每一轮都收集一次资料。

Exploration
其实随机性对于 RL 是非常重要的。因为假如没有随机性,可能有一些行为从来没有被采取过,机器也从来不知道这样是好还是不好,导致 train 不起来。所以我们有时甚至要加大随机性,例如通过增加 Entropy、给 Actor 的 parameter 增加噪音等。让模型充分探索可以采取的行为。

Actor-Critic
What is Critic
Critic 的作用就是未卜先知。给定一个 observation 和一个 actor,他要预测接下来 actor 可以获得的 discount cumulated reward。

How to Train a Critic
-
Monte-Carlo based approach:

-
Temporal-difference approach:

-
MC vs TD:不同方法可能有微妙差异

这是因为 TD 假设 和 是没有相互关联的。
Version 3.5
用 作为 b 的评估值。

为什么?

因为 Value Function 计算的是这个 Observation 之后的期望 reward,我们把样本中采取的某一个特定行为的 reward 和这个做对比,就知道这个行为是优于平均还是差于平均了。
Version 4
但是刚刚,我们是给某一个确定的采样的情况减去平均,这不一定很准确,所以我们可以也用期望预测未来的得分,而不是固定的采样得分。
这也就是 Advantage Actor Critic

Training Tip
共用参数提取特征

Outlook
Reward Shaping for Sparse Reward
假如 reward 在互动过程中,几乎都是 0,只是偶尔有一个很大的 reward,又该如何呢?
这时候我们的模型会觉得执行不同的 action 根本没差别,也就是很难 train 了

这时候我们需要定义一个额外的 reward 来引导机器学习。
E.g. 训练机器玩 VizDoom

因此可见,reward shaping 的设计需要设计者的 domain knowledge
还有一种叫做 Curiosity-based reward shaping 的方法,他要求机器要不断探索新事物,探索加分(但是必须是有意义的信息,而不能是杂讯等)
No Reward: Learning from Demonstration
在真实的、非人造的环境中,reward 往往很难定义,而如果 reward 定义不好,机器可能会学到奇怪的逻辑,展现奇怪的行为。
Imitation Learning
因此使用方法:Imitation Learning,让机器在没有 reward 的情况下和 environment 互动。

Not Supervised Learning (Behaviour Cloning)

因为无法覆盖所有可能的情况,会有机器在资料学不到的情况。
同时,也有的行为是人类的特质,不需要机器模仿、完全复制。
最重要的,机器的能力是有限的,有的行为可能不能完全克隆下来,所以可能导致机器的半调子行为产生坏的影响。
Inverse Reinforcement Learning
所以我们还有另一种办法:让机器自己定 reward

也就是先反着进行 RL,利用专家的示范,让机器先学习如何评价行为,学习出来 Reward Function,再用来进行 RL。
如何做呢?

(注意!The teacher is always the best 是指老师的行为可以获得最高的 reward,但是不代表要完全模仿老师的行为)

这就更像是 GAN(Generative Adversarial Network) 了!
Outlook
