我们不仅仅需要机器给我们答案,还需要机器告诉我们得到答案的理由。
所谓好的 Explanation,就是让人高兴的 Explanation。
Catagories
- Local Explanation: Why do you think this image is a cat?
- Global Explanation: What does a “cat” look like? (Not referred to a specific image)
Local Explanation
Which Components is most Important
也就是找到输入的哪个部分,对于机器的决策最有影响力。

两个方法:
-
通过 mask,遮挡某一部分,计算此时机器做出正确分类的概率,绘制热力图。分类的关键特征如果被遮挡,那么正确分类的概率会变低,由此可以看出机器是根据什么进行分类的。

-
Saliency Map:计算 Loss 对输入的每一维度的偏微分,即可以计算出哪些维度对输出的影响更大。
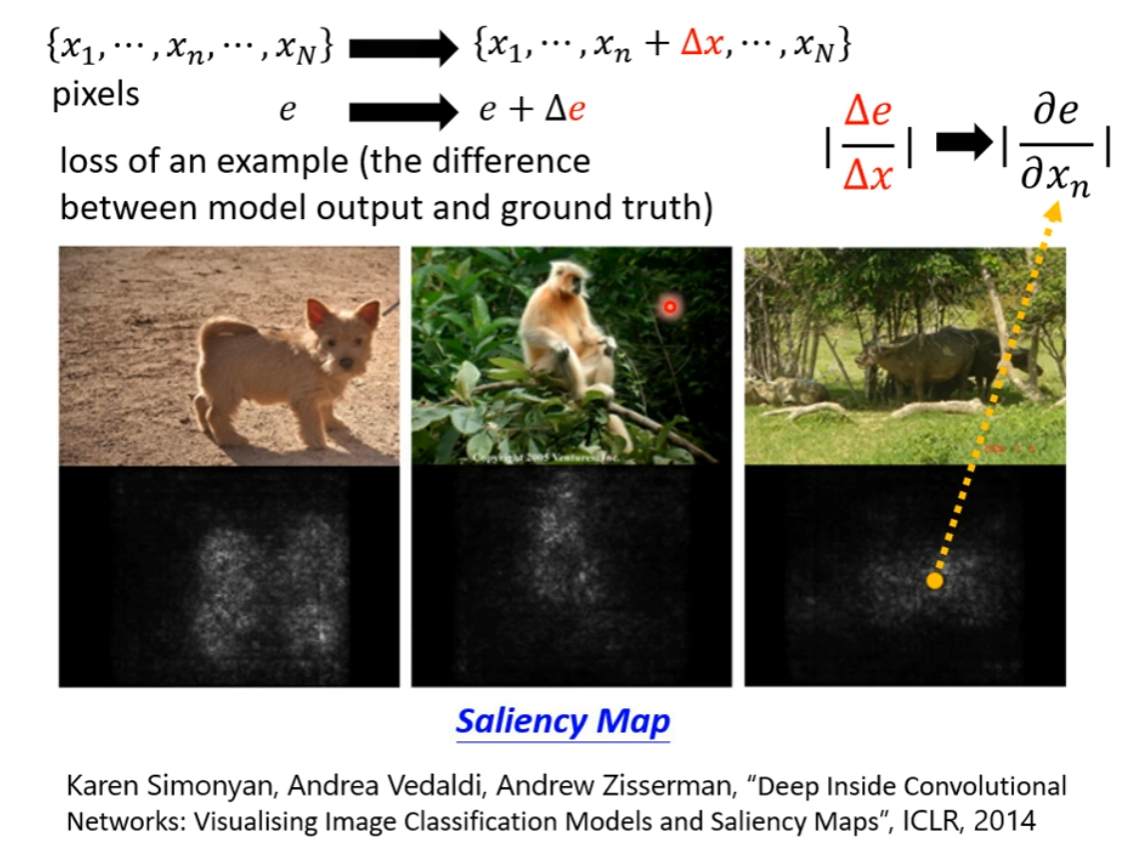
更进一步,加噪声,多次计算取平均,得到 SmoothGrad 计算的 Saliency Map

但是梯度也不总反应重要性,因为可能面临饱和,也就是达到一定限度后,一些 component 的微小变化对判断不再有大的影响了,因此有 IG 的技术解决这个问题。

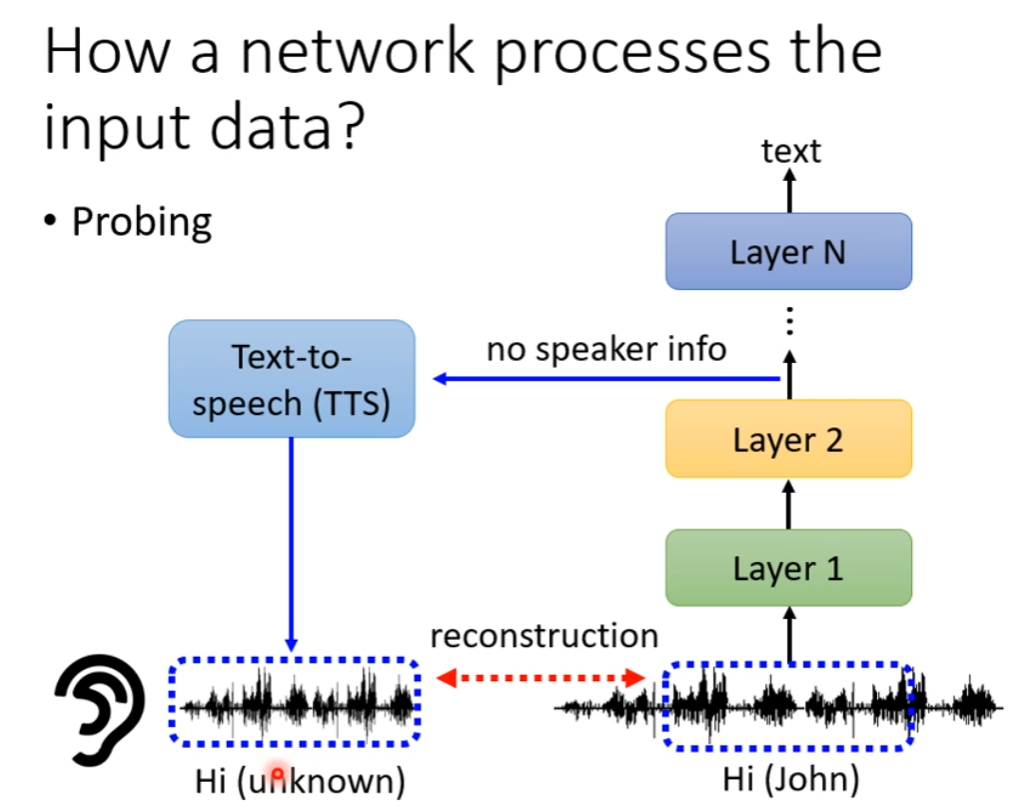
How a Network Process the Input Data
-
Visualization

-
Probing

Global Explanation
不针对某一个特定的输入,而是解释整个模型。
如果输入里面有机器要检测的特征,那么就会在隐藏层输出更多的 Large Values
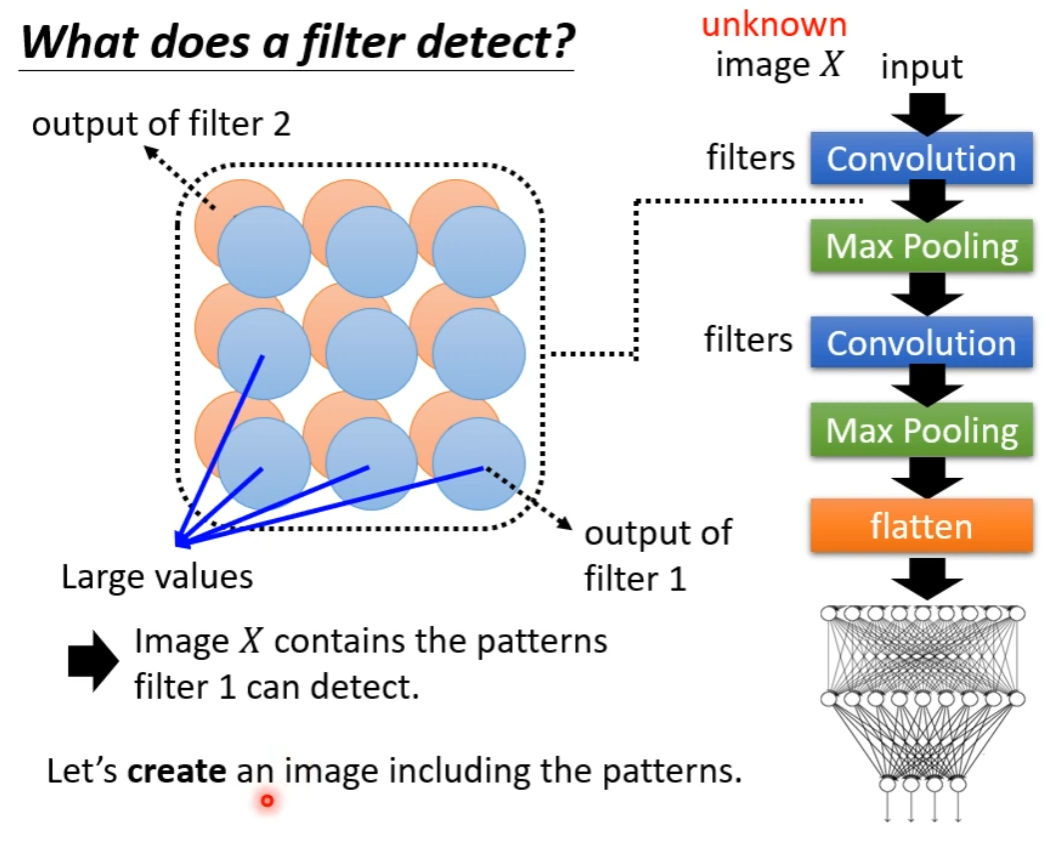
而我们现在并没有这样的一个输入,因此要直接创造一张包含机器要检测的特征的输入,藉由这样的输入,我们就可以知道机器要检测的特征了。
我们可以把输入当作未知参数,解决这个优化问题
可以在隐藏层,对某一层的神经网络做:

或者对整个模型做?

这样的噪声图竟然被高概率识别为数字,参见 Adversarial Attack。所以通过计算让输出某一类别概率最大化的输入,往往并不能看到机器理想期待的输入。
所以我们要加一些限制:

实际应该是 其中 作为约束项,要求 更像一个正常的输入,其定义是根据我们对正常的输入的特征的理解(例如此处,就是要求 像一个数字,而数字笔画不多,所以要求白色笔画部分尽量少)
或者,我们可以利用 Generator,例如:GAN、VAE 等等去做:
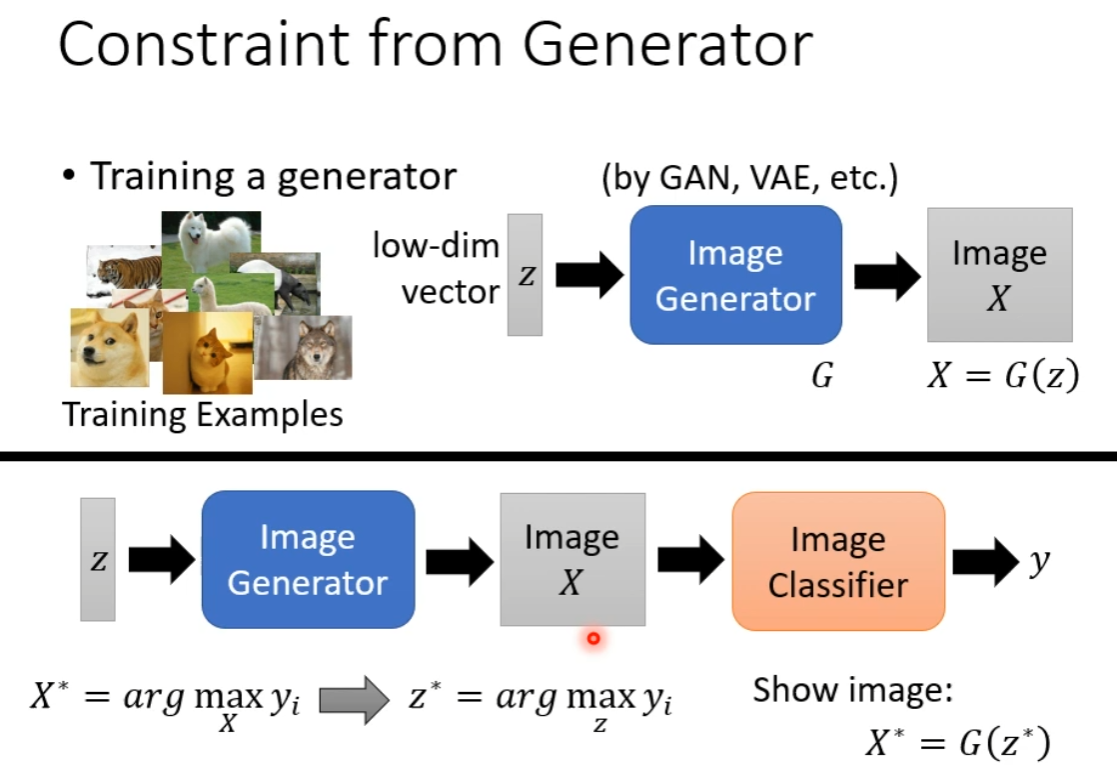
通过找到 ,然后 即为所求的,使得模型输出最大化的输入
Outlook
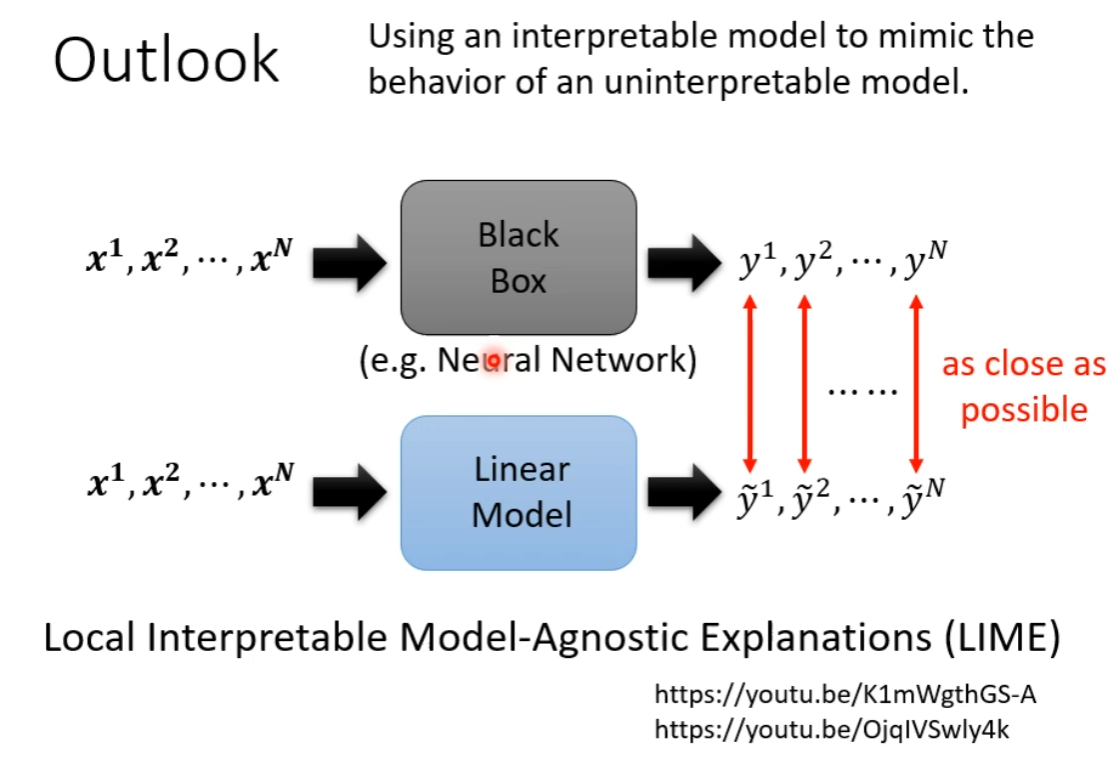
LIME:一种 Local Explanation 的方法
通过训练一个和复杂模型行为类似的线性模型,然后研究简单模型,来解读复杂模型。
有些类似于函数的一阶泰勒展开一样,在局部用线性模型逼近,从而可以得知一个输入周围的变化趋势,也就是输入微小变化如何影响输出。
相对于直接求导,最大特点是模型无关性,不需要知道模型具体内容,甚至不关心其是否可导,而是可以真正的视为黑箱来处理