问题
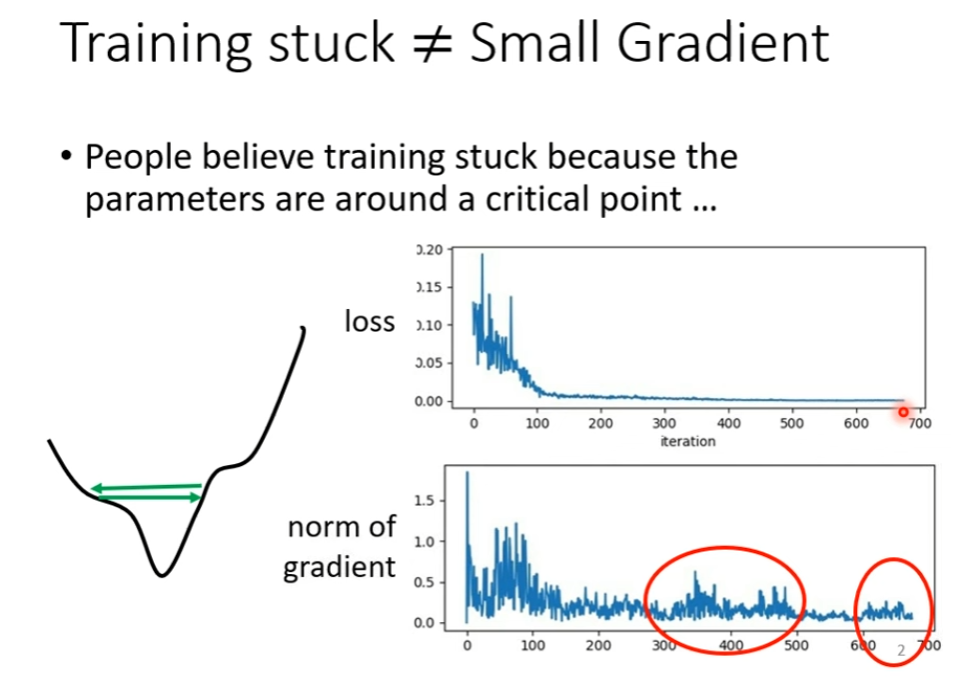 事实上,用一般的 Gradient Descent 方法,我们的训练往往走不到 Critical Point 就停止了。
事实上,用一般的 Gradient Descent 方法,我们的训练往往走不到 Critical Point 就停止了。
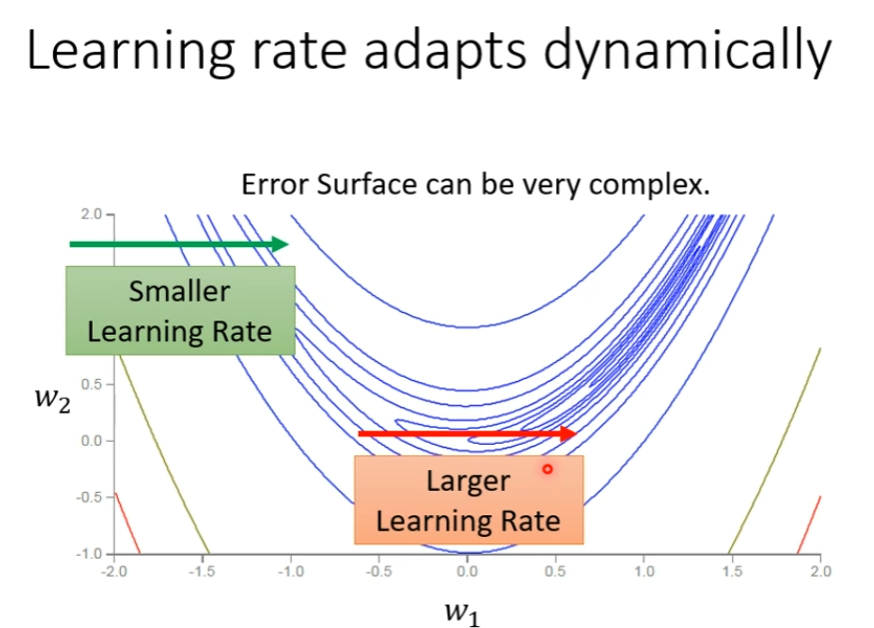
学习率大了,步子太大,震荡;学习率小了,步子太小,训练不动
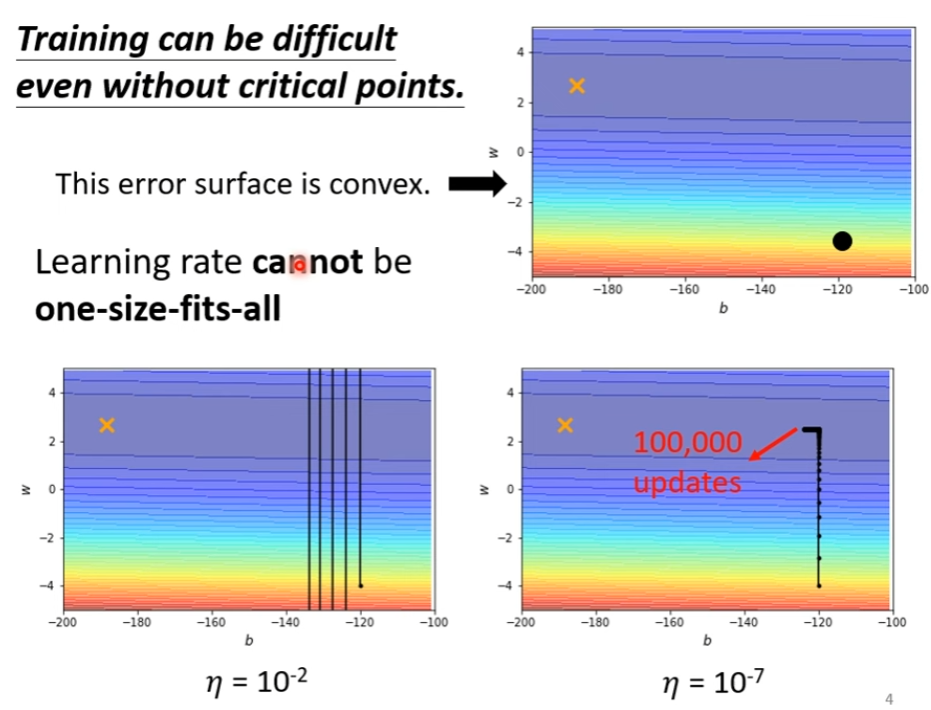
因此要客制化 Learning Rate!
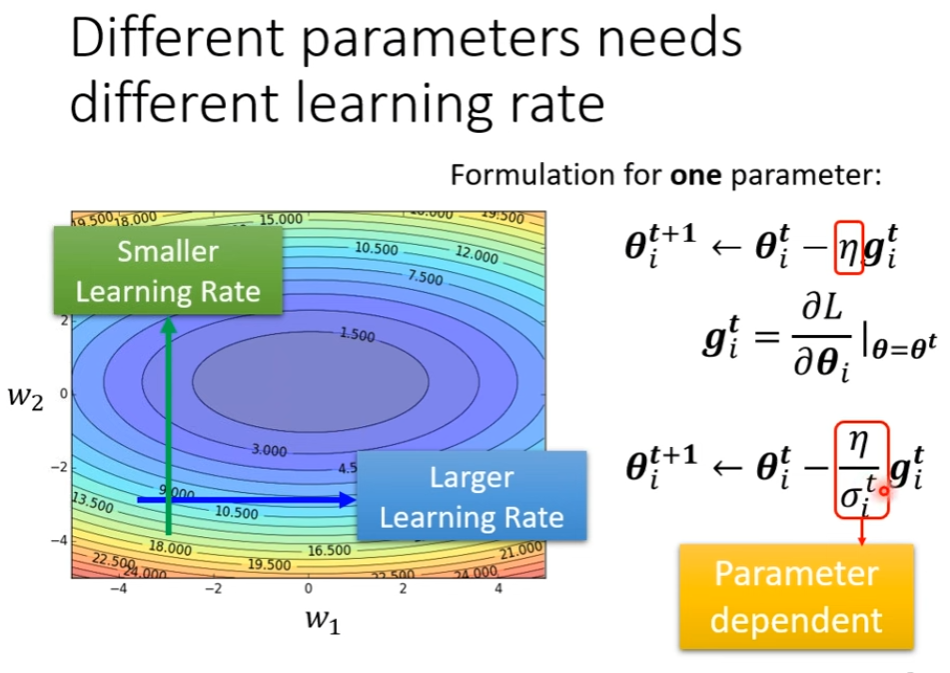 代表其是由参数和迭代次数决定的。
代表其是由参数和迭代次数决定的。
计算方法
均方根:Adagrad
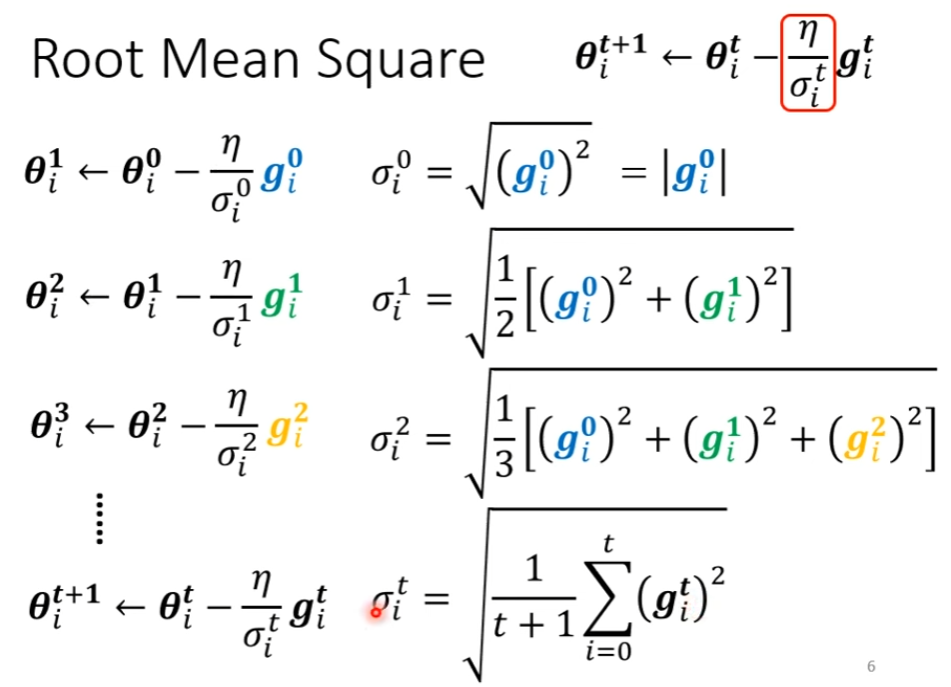
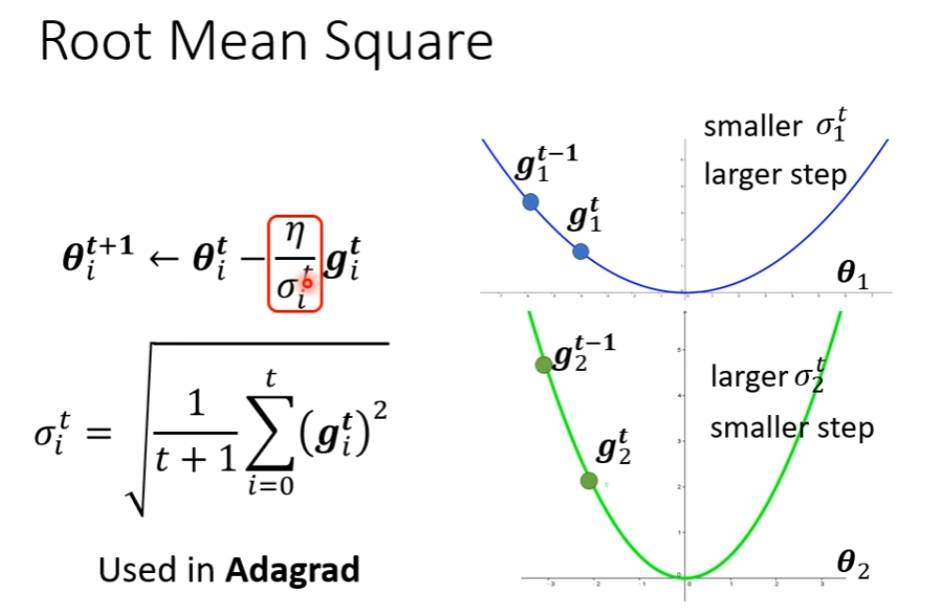
但是仍需要改进,就算是同一个参数,需要的 Learning Rate 也会因为 Gradient 大小改变而需要改变。
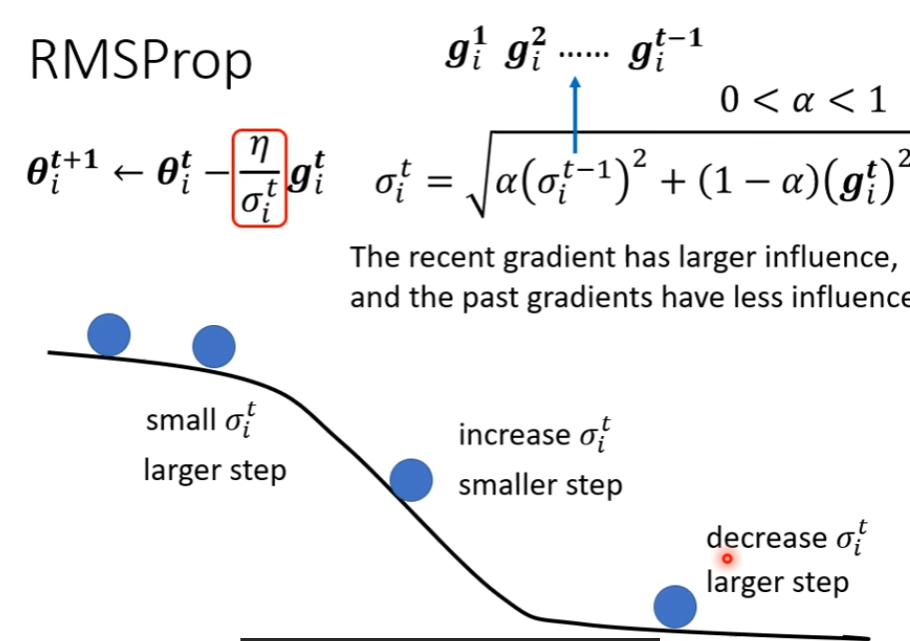
RMSProp
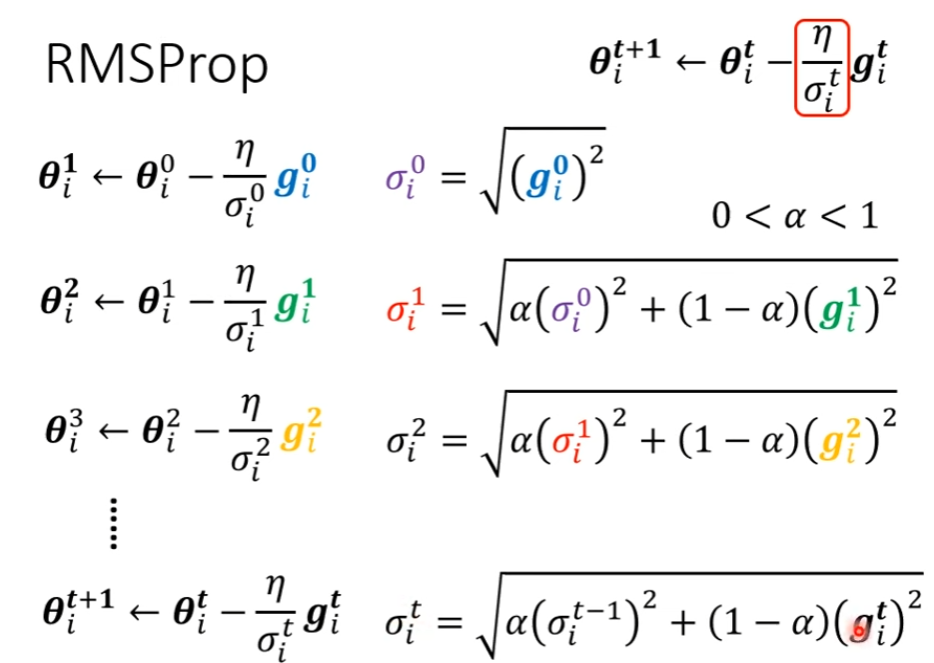 我们可以自己决定算出来的 权重的占比,让他更看重最近新算出来的 Gradient
我们可以自己决定算出来的 权重的占比,让他更看重最近新算出来的 Gradient
Adam = RMSProp + Momentum

EMA
事实上,Momentum 和 RMSProp 本质都是 EMA。
Adam 维护了两个“关于梯度的记忆”,都是指数滑动平均(EMA):
- 一阶 EMA(向量):
- 梯度本身的指数滑动平均
- 记住运动的“方向和趋势”(也影响大小)
- 类似“惯性”
- 二阶 EMA(逐坐标标量):
- 梯度平方的指数滑动平均
- 记住这个方向“通常有多陡”
- 决定你在这个方向上“该走多大一步”
- EMA:
- Momentum (一阶 EMA):
- RMSProp(二阶 EMA):
Bias Correction(Adam 除了 RMS 和 Momentum 以外的一个改进):
- Adam:
Adam 变体
- AdamW(L2 正则化时,weight decay 不进入 EMA)
- RAdam(Adam + 自动 warmup —— rectification)
- 早期:行为类似 Momentum SGD
- 后期:行为类似 Adam
Example
 爆炸是因为 过小,导致更新较大
爆炸是因为 过小,导致更新较大
可以依靠 Learning Rate Scheduling 解决
- Learning Rate Decay

- Warm Up
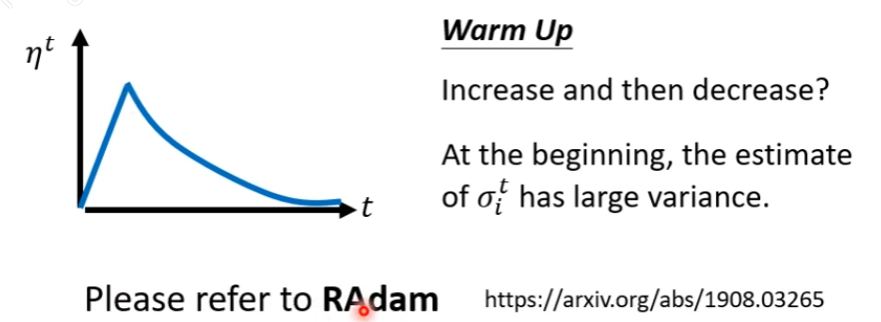
 一个可能的原因是,由于 是一个统计数据,一开始并不准确,所以需要先缓慢移动,探索、收集数据,然后再逐步提升学习率,开始快速优化、Decay
一个可能的原因是,由于 是一个统计数据,一开始并不准确,所以需要先缓慢移动,探索、收集数据,然后再逐步提升学习率,开始快速优化、Decay