Recursion is the root of computation since it allows us to describe complex processes in a very simple way.
— John McCarthy
任务背景
本单元的任务是: 通过对数学意义上的表达式结构进行建模, 利用递归下降法, 完成包含完成双变量多项式的括号展开, 指数函数, 自定义函数和三元逻辑判断结构, 求导运算, 递推函数等复杂结构的多变量表达式的展开与化简.
程序结构分析
- 程序架构
cn.edu.buaa.oo
├── App
└── component
├── analytic
│ ├── Basis
│ ├── Pair
│ └── Polynomial
├── factor
│ ├── Factor (Abstract Class)
│ ├── ExponentialFactor
│ ├── ExpressionFactor
│ ├── NumberFactor
│ ├── PartialFactor
│ └── VariableFactor
├── function
│ └── Function
├── parser
│ ├── Lexer
│ ├── Parser
│ ├── Preprocessor
│ └── Token
├── utils
│ └── InputUtil
├── Expression
└── Term我采用多级包结构, 根据类的功能相关性将其归为不同的包, 从而来管理不同的类, 使得代码的目录与依赖关系更为清晰, 相较于扁平目录更易于管理和维护.
主要的包为:
cn.edu.buaa.oo: 总包, 下有主类App, 与各个功能部件的包component.component:analytic: 关于多项式的数据与逻辑封装的包.factor: 关于各类因子的数据与逻辑封装的包.function: 关于函数的读取与存储的包.parser: 关于输入多项式的读取, 解析处理的包.utils: 静态工具类包.Expression,Term: 两个独立的类, 是题目表达式和项层级的数据与逻辑封装.
下面我们来分析代码的架构与逻辑关系.
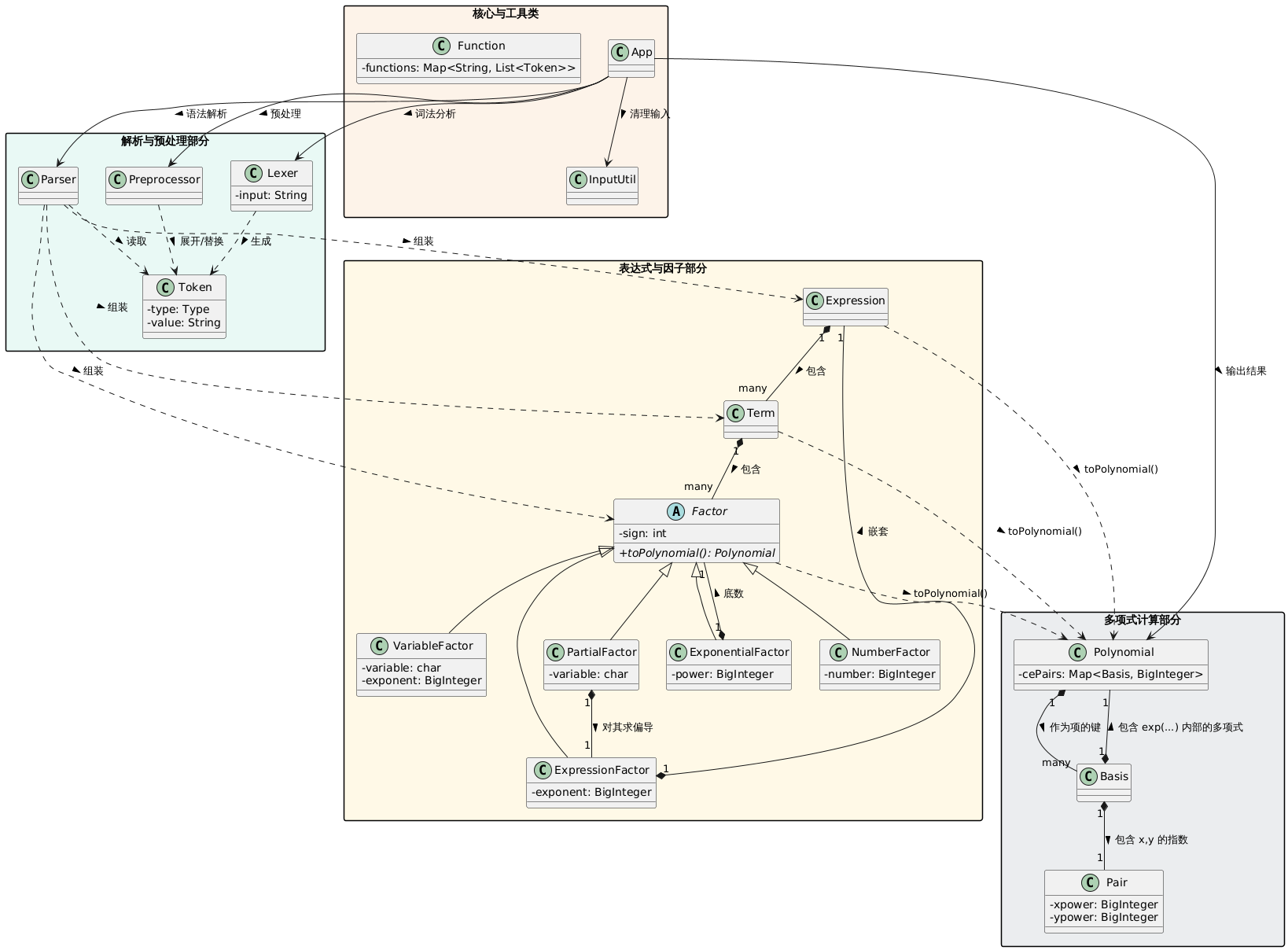
在我的程序设计中, 接收到输入后, 首先由工具类 InputUtil 进行去除空白符等处理, 随后交给解析与预处理部分.
解析与预处理部分中, 将 Token 作为通信的媒介.
首先由 Lexer 将 String 解析为 Token 的 List, 从而避免后续处理流程关注 Token 的具体形式, 而只需要关注其类型.
而后, Preprocessor 进行 Token 的展开与替换. 考虑到作业中, 函数, 梯度, 三元表达式实际都是编译期确定的量, 完全不需要表达式其余部分的语义信息, 而可以在 Parser 解析前直接处理. 因此它将函数, 梯度, 三元表达式替换为具体的 Token 列表, 使得 Parser 根本不必关注这三种结构, 而只需要负责 Expression, Term, Factor 的语法树解析.
而 Parser 正是如此做的, 将 Token 流组装为表达式层次结构.
而进入到表达式与因子部分, 实际就是一系列组合和继承关系: Expression 由 Term 组成, Term 由 Factor 组成; Factor 有各个子类. Parser 解析时是自上向下, 而在表达式转化为用于计算的多项式时, 是自下向上的: Factor 变为 Polynomial, 而 Term 只需要用乘法将其串联; Term 变为 Polynomial, 而 Expression 只需要用代数和将其串联, 从而得到了最终的多项式.
这就是最后的多项式计算部分的功能. 它支持多项式的代数和, 乘法, 乘方运算, 可以在表达式转化过程中进行化简计算; 它同时实现了 toString() 方法, 将化简后的多项式打印输出. 这里的数据使用了一种标准展开式的数学结构: 多项式由多项单项式构成, 表示为 Map<Basis, BigInteger>. 键是 Basis 作为变量和指数函数的乘积部分, 值是 BigInteger 作为系数. Basis 由两部分组成: Pair 负责记录 x 和 y 的幂次; 另一个 Polynomial 负责记录嵌在 exp() 内部的多项式. 通过这样的形式, 我们可以方便的进行数据存储和化简合并.
从而, 我们的数据经过程序运行, 由化简前的字符串输入, 变为化简后的字符串输出.
- 代码规模
以下数据基于插件 MetricsReloaded, 和能工智人计数与手算统计获取.
| 类 | 属性(个) | 方法(个) | 类规模(行数) | 备注 |
|---|---|---|---|---|
App | 0 | 1 | 24 | |
Basis | 2 | 7 | 51 | |
Pair | 2 | 10 | 86 | |
Polynomial | 1 | 16 | 169 | |
Factor | 1 | 5 | 16 | |
ExponentialFactor | 2 | 2 | 16 | |
ExpressionFactor | 2 | 2 | 13 | |
NumberFactor | 1 | 2 | 11 | |
PartialFactor | 2 | 2 | 13 | |
VariableFactor | 2 | 2 | 15 | |
Function | 1 | 3 | 26 | |
Lexer | 3 | 3 | 83 | |
Parser | 2 | 13 | 110 | |
Preprocessor | 2 | 13 | 187 | |
Token | 2 | 3 | 34(+25) | 内有一枚举类 TokenType |
InputUtil | 0 | 2 | 18 | 静态工具类,构造方法私有 |
Expression | 1 | 3 | 17 | |
Term | 1 | 3 | 17 | |
| Total | 27 | 92 | 931 |
首先从代码量来看, 总代码量尚可, 控制在 1000 行内, 但分为 18 个类(除枚举类), 尽力将逻辑分散, 因此比例比较健康, 避免包办一切的上帝类.
而具体到每一个具体的类, 可以发现, 代码主要集中于 Polynomial 类和 Preprocessor 类.
其中, 前者为本次作业的核心, 负责表达式的存储和计算; 后者主要负责了后两次作业中的代入功能, 职责单一且内聚, 作为 Lexer 和 Parser 的中介.
因此属于是必要的复杂性, 处理主要的业务逻辑; 而其他类则主要作为辅助, 完成其余职责, 并且作为潜在的扩展接口.
并且, 即使是两个较大的类, 方法数也同时比较多, 每个方法的平均行数也因之较小. 这是因为我涉及了一些私有辅助方法, 提取出了重复的或者复杂而不适合在方法主干展开的逻辑.
尽管这增加了一些调用层级, 但是使得这些大类的代码也不至于过于臃肿而难以认知.
而表达式经过 Parser 解析后的数据的存储和后续处理, 所涉及一些类, 也有一些代码规模的考量.
关于 factor 的设计, 则充分利用了 OO 的多态性, 抽象类 Factor 用 16 行定义了 5 个方法(包括一个抽象方法 toPolynomial()), 很好起到规范的作用, 并且将代码分散到各个小的子类.
Expression 与 Term 则也同样较小, 甚至代码量一致, 对应了题目中二者虽然处于表达式不同层级, 但是数据结构和承担职责的类似: Expression 是 Term 相加, Term 是 Factor 相乘, 而他们都通过调用 Factor 的 toPolynomial() 实现自身向 Polynomial 类的转化.
- 代码复杂度
项目整体的圈复杂度较低, 总值为 217, 平均值为 2.38, 属于合理范围. 而具体到细节, 不同类由于承担职责不同, 复杂度因之高低不同.
- 解析器部分: 包的总圈复杂度高达 91,占全项目的近 42%.
- 表达式与因子部分: 类的 WMC 均只有 3 上下, 平均圈复杂度在 1.36 左右. 这里的抽象程度高, 功能划分合理, 充分利用了面向对象的思想.
- 多项式计算部分: 该包总圈复杂度为 85.
Polynomial是全程序最大的类, WMC 为 39. 但是, 真正负责数学计算的方法的复杂度非常低, 圈复杂度仅为 1 到 4, 而这个包 80% 的复杂度都在toString()一类的方法上.Polynomial中monomialToString()圈复杂度为 9,toFactorString()圈复杂度为 6,toString()圈复杂度为 8;Pair.toString()圈复杂度为 9.
下面, 我们来分析一下重点的类, 同时也是复杂度相对更高的类, 包括解析与预处理部分和多项式计算部分.
| 类 | WMC | OCmax | OCavg | 分析 |
|---|---|---|---|---|
Polynomial | 39 | 6 | 2.44 | 系统最复杂类. 主要负责底层数学运算与结果格式化, 包含了大量的边界条件处理 |
Pair | 23 | 8 | 2.30 | 维护 (x, y) 变量及其指数,其复杂性集中在字符串输出和相等性判断上 |
Basis | 11 | 3 | 1.57 | 起到单项式的作用, 记录变量 x, y, exp 的指数, 和 Polynomial 递归嵌套 |
Lexer | 17 | 14 | 5.67 | 词法分析器, 方法少但平均复杂度极高, 包含了一个巨大的字符匹配分支流 |
Preprocessor | 32 | 7 | 2.46 | 系统第二复杂类. 直接操作 Token 列表进行展开和替换, 逻辑嵌套深 |
Parser | 28 | 9 | 2.15 | 递归下降解析器的核心, 负责将 Token 流组装为 AST, 大量的条件分支用于类型判断. |
这两部分六个类, 内部是程序的主要逻辑, 因此同时也是程序主要的复杂度来源.
其中 Polynomial 和 Pair 本身在运算的方法上, 复杂度并没有很高, 主要是处理格式化输出的边界.
其实此处有一个优化点: 可以设计一个 PolynomialFormatter 类, 专门负责多项式打印, 而使得其余类只需要关注运算逻辑, 而不必处理复杂的输出. 本次作业由于以及输出复杂度尚可, 加之开发临近末尾, 因此将这些功能打包在一起勉强可以接受, 故我没有进行进一步解耦, 但这无疑是一个优化方向.
而解析器部分, Lexer 虽然复杂度高, 却是虚胖, 主要是 Token 识别的分支语句造成的, 实际逻辑十分简单, 阅读也并不困难. 是出于词法解析本质需要大量判断而导致的复杂度, 我已经通过定义 map, 处理一部分类似 ( 的 Token, 但是仍旧需要一些判断处理诸如数字的 Token, 这个目前没有很好的解决方法.
Parser 的复杂度相对来说并不高, 只是 parseFactor() 方法因为涉及解析不同类型的因子而比较复杂. 其实这里也有一个优化方向: 使用工厂方法, 托管 Factor 的实例化逻辑, 也使得 Parser 不用再内部尝试确定因子类型并且调用不同方法实例化. 如果未来还有新的因子, 也不必修改 Parser, 而可以只在工厂类中增加新的因子类. 这样会更符合开闭原则.
主要是 Preprocessor 类, 我认为是一种架构设计取舍. 在我的设计中, Preprocessor 负责函数, 三元运算符, 梯度的展开.
因此, 实际上在后两次迭代, 我的 Lexer 和 Parser 基本没有新增逻辑, 而基本都是在 Preprocessor 中进行的功能增加与修改.
在我们的作业中, 函数, 三元运算符以及梯度, 都是”编译期”确定的”常量”, 实际上就是一种宏替换, 完全不需要额外语义信息.
因此我受 C 语言启发进行分层处理, 把自定义函数 f(x), f{n}(x), 梯度操作 grad、三元运算符 ? : 视作或宏.
从而使得 Parser 得到了保护, Parser 根本不需要知道什么是 grad,不需要知道什么是三元运算或者函数,它只要解析最纯粹的加减乘除、指数求导即可.
换言之, 我认为并非 Preprocessor 过于复杂, 而是我们的任务中, Lexer 和 Parser(尤其是后者)较为简单, 并没有复杂的任务要求, 因此逻辑相较于 Preprocessor 反而更轻量.
但反之, 假若面临更新的迭代, 出现运行时函数, 运行时确定的条件等, 这样的架构会更好: Preprocessor 可以忽略这些特定的运行时函数而不展开, 原封不动地传给 Parser, 在表达式中新增一个 RuntimeFunctionFactor 即可. 宏展开和运行期解析被物理隔离在了两个完全不同的类(Preprocessor 和 Parser)里, 互不干扰.
当然, 这不意味着我的 Preprocessor 设计很好. 实际上, 此类中有大量复杂度是由于 Preprocessor 需要自己对一维的 Token 列表进行维护, 遍历, 匹配括号.
这实际上可以交给一个独立的类 TokenCursor, 进行遍历位置的维护, 括号的匹配, 参数的提取, 从而使得 Preprocessor 的复杂度更低, 只需要用参数进行替换, 达到一种”声明式”的效果.
架构迭代
在作业的迭代中, 我的核心架构逻辑迎来过一些小规模的重构.
第一次迭代
本次作业需要完成的任务为:读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 3 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。 在本次作业中,展开所有括号的定义是:对原输入表达式 E 做恒等变形,得到新表达式 E′,且 E′ 中不含有字符 ( 、 )和空白字符 。
我主要是仿照课程组公众号的架构进行设计, 经典的 Lexer -> Parser, Expression -> Term -> Factor 架构, 并且表达式的组分都实现了 toPolynomial()方法, 最终转化为 Polynomial 进行计算和输出.
第二次迭代
本次作业需要完成的任务为:读入一个自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用和新增的选择式因子的表达式,输出恒等变形展开所有括号后的表达式。 在本次作业中,展开所有括号的定义是:对原输入表达式 E 做恒等变形,得到新表达式 E′。其中,E′ 中不再含有自定义函数和选择式因子,且只包含必要的括号(必要括号的定义见公测说明-正确性判定)。
本次作业增加了指数函数, 我将其定义为一个新的因子, ExponentialFactor. 并且我将 Polynomial 内部的 Map<Integer, BigInteger> 改为 Map<Basis, BigInteger>, 而 Basis 内部为 BigInteger 的变量幂次和 Polynomial 的 指数函数幂次.
而新增的选择式因子和函数因子, 我并没有为他们定义新的 Factor 类, 而是如前所述, 增加组件 Preprocessor 进行替换. 另外, 我还预备性的增加了 Function 静态类, 用于存储和读取函数, 为后续多函数定义做准备.
为了在 Lexer 和 Parser 之间插入 Preprocessor, 我修改了这部分代码, 定义了 Token, 并且让 List<Token> 成为三者交流的桥梁, 而不是和第一次作业一样, 随着 Parser 的消费而推进 Lexer, 返回下一个字符.
第三次迭代
本次作业需要完成的任务为:读入自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用、选择式因子和新增的求导算子的多变量表达式,输出恒等变形展开所有括号后的表达式。 在本次作业中,展开所有括号的定义是:对原输入表达式 E 做恒等变形,得到新表达式 E′。其中,E′ 中不再含有自定义函数、选择式因子和求导算子,且只包含必要的括号(必要括号的定义见公测说明-正确性判定)。
意料之外, 情理之中地引入了变量 y, 因此我将 Basis 的 BigInteger 指数换为 Pair, 内部为两个 BigInteger 对应 x, y.
并没有出现我预料中的多函数, 而是地推函数, 不过我还是得以复用上次 Function 类, 把 f{n} 作为不同的函数签名, 并且进行记忆化, 从而提升了复杂递推函数解析效率.
至于求导, 我将 grad 直接在预处理中转化为 dx 与 dy, 而这两者定义为新的 PartialFactor, 通过多项式相关类实现了求导方法.
新的迭代情景
例如未来出现多函数定义, 例如 g(x), h(x), 我可以将他们在 Function 类内注册, 并且和 f(x) 一样处理分析.
又例如如果出现运行时才能计算出结果的选择式或函数, 可以在 Parser 增加逻辑, 解析为新的因子, 然后在内部实现计算逻辑.
Bug 分析
本次作业中, 我的 bug 都出现在字符串输出中.
在第二次作业, 处理 exp 内为一个单因子的时候, 错误处理了内部的单因子为 1 的状况.
第三次作业中, 新增变量 y 后, 加之判断条件比较复杂, 我对于 exp 内部的表达式是不是单因子的判断出现错误, 不但条件完全写反了, 还忽略了对 y 的判断, 因此大量出现缺少必要括号的情况.
Bug 修复中, 我采用了 Stream 库, 按照 Boolean 的 false 数累加计算 Basis 非 1 因子的个数, 以此判断是否含有乘积. 修复了 bug 的同时提升了可读性, 避免了过于复杂的布尔表达式.
因此正如我之前所言, 我的字符串格式化相关逻辑, 相比其他方法, 尤其是同类内其余的方法, 复杂度高, 特判更多, 且还混杂在 Polynomial, Basis, Pair 几类中, 导致这几类的复杂度也飙升, 着实难以维护, 此次作业三次迭代就已经如此勉强, 因此可以设计一个 PolynomialFormatter 类, 专门负责多项式打印, 而使得其余类只需要关注运算逻辑, 而不必处理复杂的输出.
Hack 分析
我并没有热心于 Hack, 没有花费大量时间阅读他人源码, 尤其是每人风格不同的同时, 后期代码量比较高, 逐个阅读并不现实, 因此我以黑盒攻击为主.
Hack 阶段, 我首先先会尝试在测试自己程序时, 发现的一些存在引发潜在错误可能的数据点.
其次, 我会下载源码, 先交给 AI 进行粗筛, 人工确认是否为真正的 bug, 并且针对性设计数据点攻击.
最后, 我会使用更多的数据本地大量测试, 尝试找出潜在的未发现 bug.
优化分析
Handle the common case fast, and the correct case correctly.
— Butler Lampson
事实上, 我并没有做什么优化. 出于时间效率的考量, 加快开发进度, 达成 90% 的完成度就是我的目标了.
我仅仅进行了”若正项存在, 则将正项放在第一项”, “若 exp 内部的表达式为单因子, 则不加额外括号”, “忽略 1 作为乘积项, -1 作为乘积项时仅输出负号”, 几项优化.
甚至没有进行公因式提取, 遑论乘开. 主要是是出于时间成本考量, 也不想增加自己的维护成本.
大模型使用
我主要是使用 AI 进行两种任务:
- 在正确性和性能优化上, 都重复代码补全生成, 例如大量同质化的判断语句, 类似结构的类代码等, 占比约在 20% 以内.
- 辅助 bug 查找, 在自己测试之前先让 AI 广撒网搜寻一边, 自己评估修改后, 再进行人工测试, 从而快速解决一些浅显的 bug.
同时也如前所述, hack 阶段, 我也会使用 AI 进行同样的广撒网搜寻 bug.
不过由于我编写代码使用的是行间补全, 所以 AI 能力略差, 事实上基本很难生成直接可用的代码, 我上述的 bug, 核心逻辑也有一部分是 AI 自动补全后我没有发现的.
至于 bug 收集, AI 面对一些逻辑错误发现较快, 但是对于作业规则则可能常常忽视, 导致并不能完全解决所有 bug.
心得体会
OO 正课相比于先导课, 任务难度和时间紧迫程度都有了大幅上升.
这对我们的架构设计能力提出更高的要求, 唯有设计出更加符合 OO 设计原则的好代码, 有更高的可扩展性与可维护性, 方才更容易在多次迭代中保证正确, 在高强度测试中得以通过.
同时, 我对递归下降法, 词法语法都有了更深刻的理解, 增加了进行形式化建模, 将抽象定义转化为实际代码的经验.
并且, 我也增强了对代码的 review 能力, 我认为这是在 AI 时代格外重要的一项能力.
未来方向
可以对优化方向提供一些简单引导, 包括可能用到的知识参考, 帮助大家即使不熟悉相关知识, 也可以更快上手学习, 更好地提升设计能力与算法能力.