Are your networks robust to the inputs that are built to fool them?
也就是说,Network 得到很高的正确率还远远不足,还需要在面对有人试图欺骗它的时候也有高的正确率。这对于 spam classification, malware detection, network intrusion detection 等领域很关键,因为对方会试图反制我们的侦测手段。
How to Attack

加入杂讯,小到人辨别不出(图中比较大,仅为示例),然后使得机器输出错误结果(分为 targeted 和 non-targeted)

这是如何做到的?
实际上也是一个优化问题:
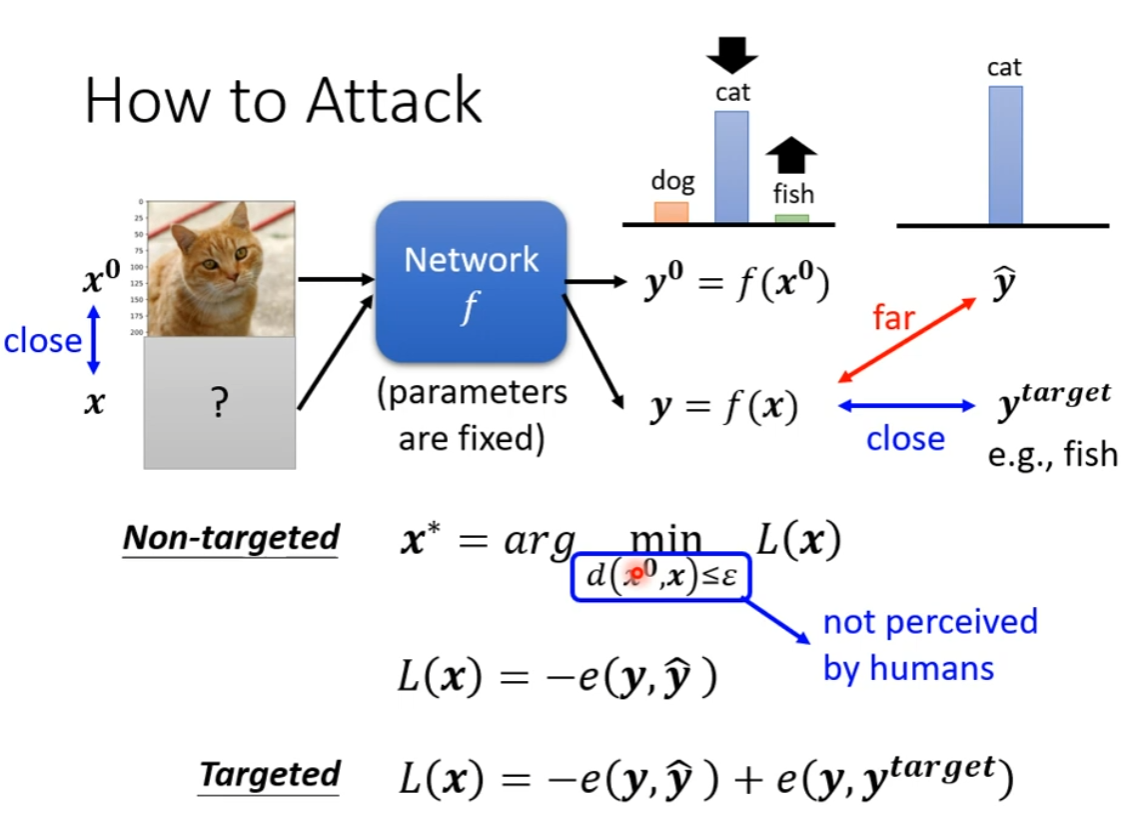
要求有二:
- 输出:
- 如果是 non-targeted,则和原正确输出差距越大越好,Loss 为负的 Entropy
- 如果是 targeted,则与原输出差距大的同时,和目标输出越小越好,Loss 为 non-targeted Loss 加上一项和目标输出的 entropy
- 输入:和原输出差距要小于人能察觉的阈值,差距常用 L-Infinity

如何训练:
不考虑输入的限制时,我们就和 train model 一样 train 就好了,只不过梯度变为 Loss 对输入的偏导数而已

再加上对输入的限制,方法仅仅是,当优化出来的输入不符合限制,就修改到符合限制,例如对于 L-infinity,就只需要一个 torch.clamp()

至于别的变形,根本思想一致,只是 Constraint 或者 Optimization method 不同
Fast Gradient Sign Method(FGSM)
一个简单攻击方法,只对输入进行一次 update
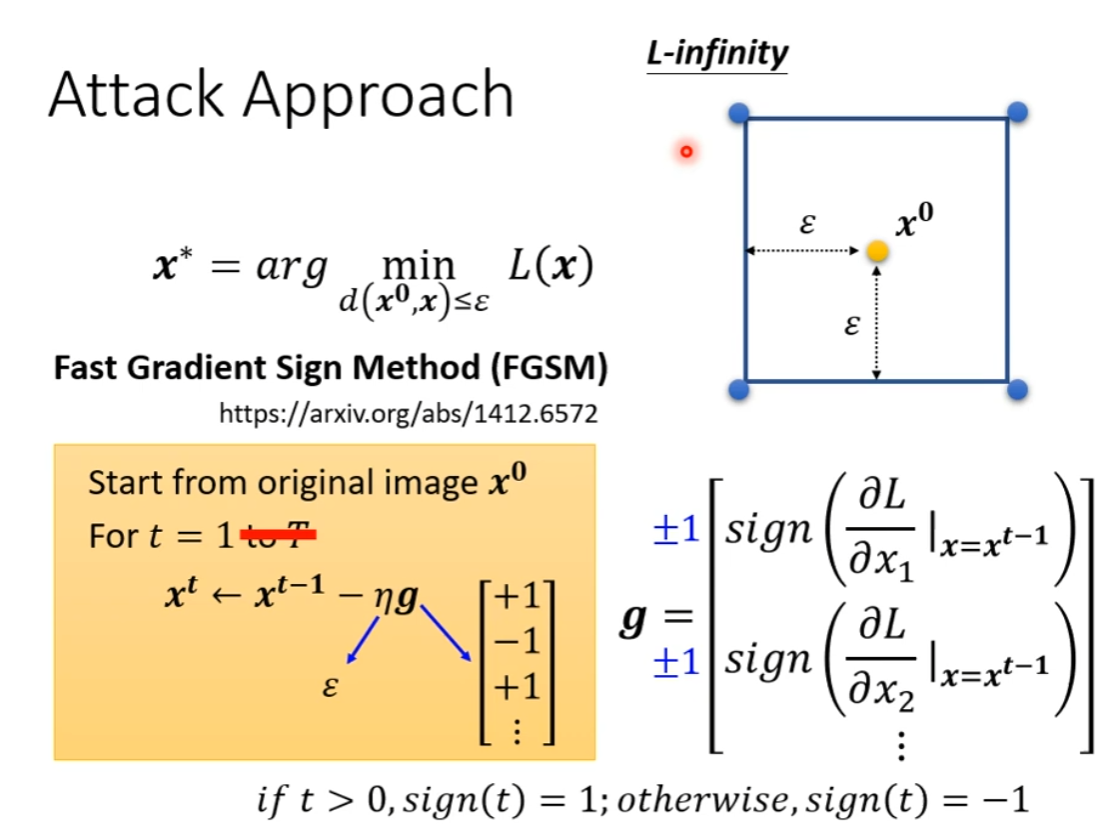
从而使得新的输入必定处于边界的角落
也可以多跑几轮,效果会更好

只是同样需要在输入超过范围的时候,将其拉回最近的角落
White Box v.s. Black Box
以上的方法属于白箱攻击,因为如果我们计算 Gradient,势必需要知道模型的参数,才能求导。
而相反,不需要模型参数的攻击手段称为黑箱攻击

方法:
- 如果知道目标模型的训练数据,用攻击目标的训练数据训练一个模型,尝试攻击这个模型,把攻击的输入投入给目标模型,尝试是否能成功。
- 如果不知道目标模型训练数据,用一些输入投入给目标模型,得到一系列输出,用这些成对资料训练一个模型,尝试攻击这个模型。
Tips:
- 一般黑箱攻击做到 non-targeted 比较容易。
- 如果使用 ensemble model,攻击成功率会大大提升。
More about Attack…
除去影像,声音、文字也可以被攻击;
也有尝试 one-pixel attack、universal attack 的;
甚至可以在物理世界中,通过一些特制的物品来欺骗机器;
还有 Adversarial Reprogramming,可以使得模型做一些本来不是训练目标的事情。
攻击也不止局限于 Testing 阶段,甚至可以在 Training 阶段开展,通过特制的看似正确的训练数据,然而机器一旦学习后,对某些特定数据就会“开后门”误判。
Defense
Passive Defense
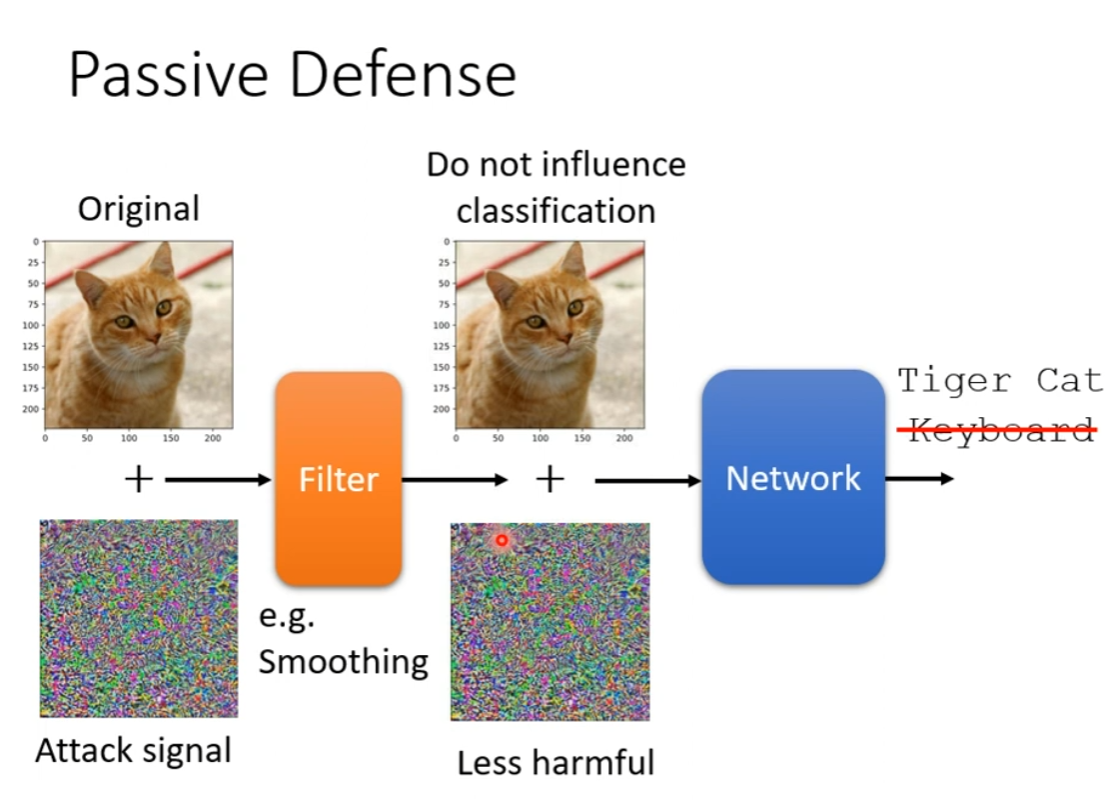
可能稍作一些模糊化就可以达到不错的效果

虽然有一些副作用
还有更多方法:

不过 Passive Defense 具有很大的弱点,例如模糊化,只要被攻击者知道会进行这种操作,就可以让其将其视为 network 的第一层,在训练攻击数据时考虑到。
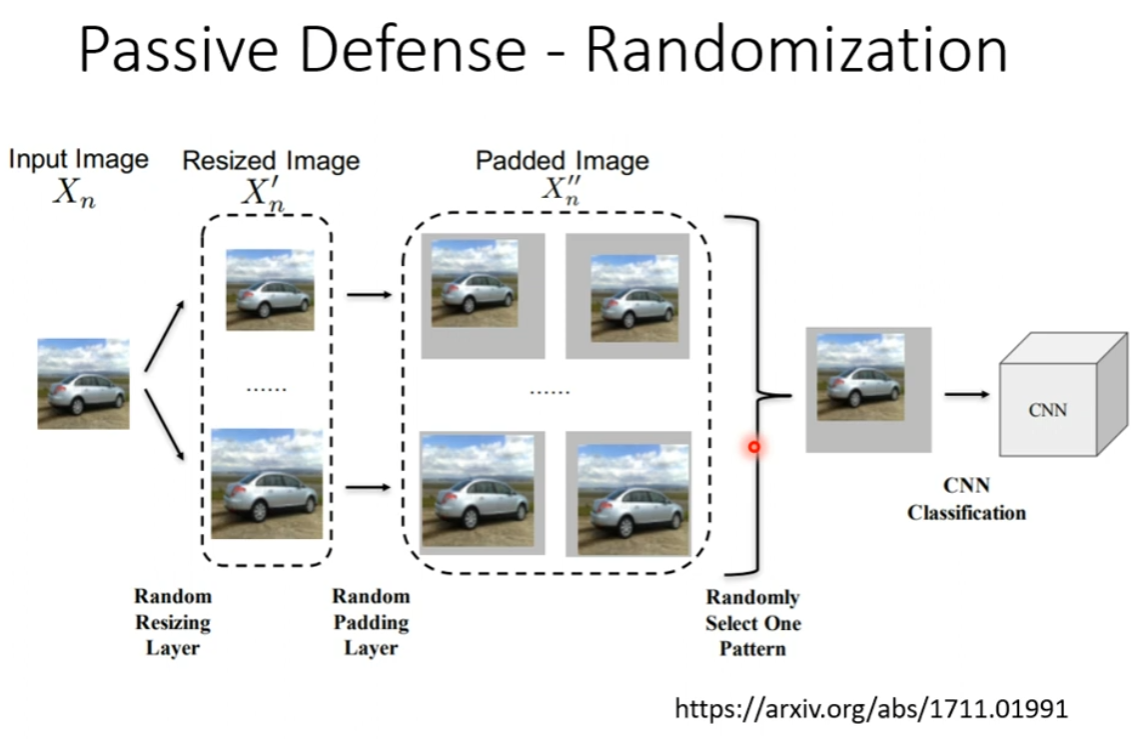
还有更增强的方法:随机化,随机改变输入图片
Proactive Defense
在训练模型的时候就训练一个不容易被攻破的模型,也就是训练阶段就对模型进行攻击

也是一种 Data Augmentation
不过面对一种训练时没考虑的,新的 attack algorithm,就可能不奏效了
并且消耗的计算资源比较大,为了应对这个问题,有人提出了 Adversarial Training for Free